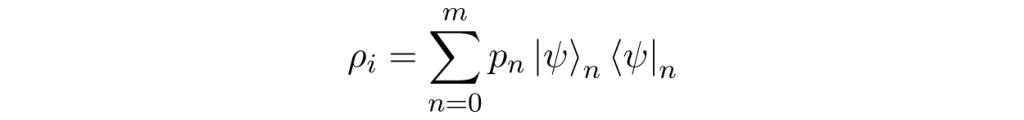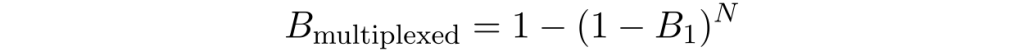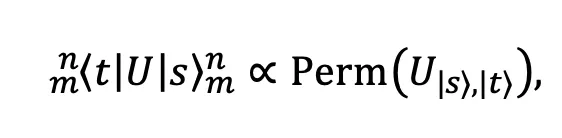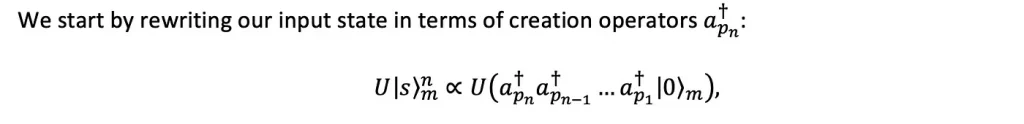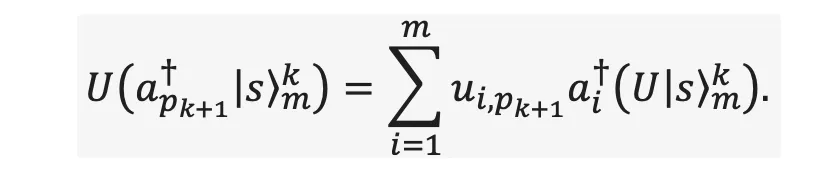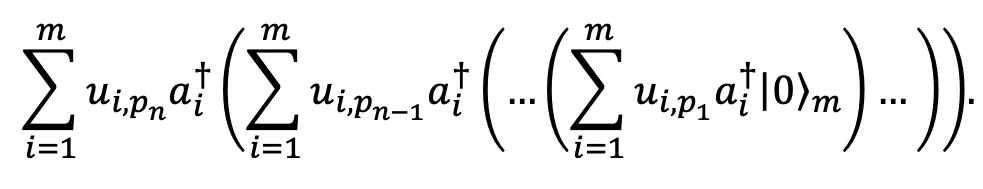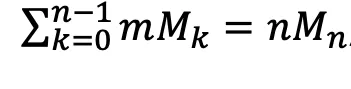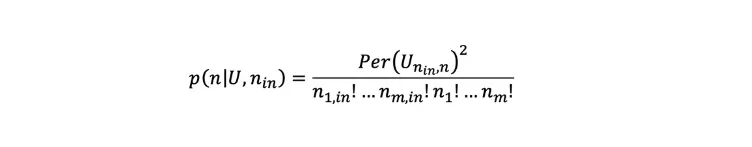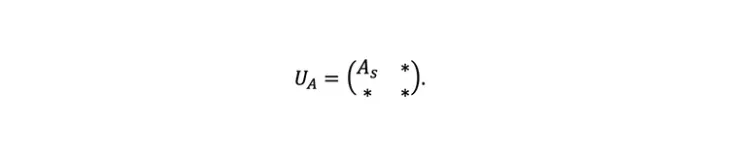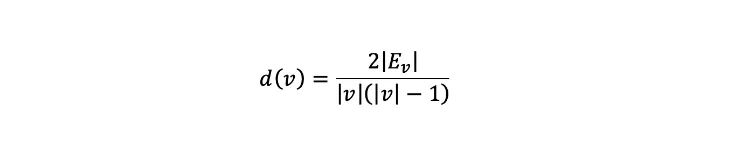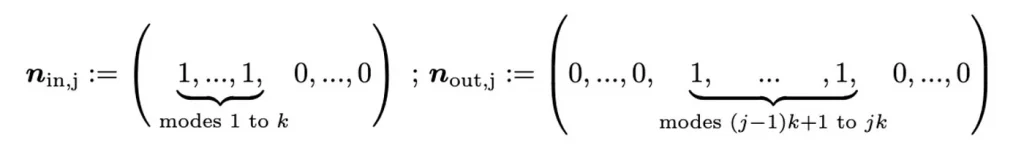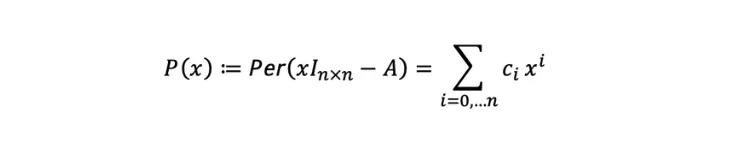What is randomness? And how can we generate it? Both questions — the first mathematical, the second technological — have profound implications in many of today’s industries and our everyday lives.
Imagine that we wanted to make a random list of 0s and 1s. This list could be used to protect your medical records as a keyword, could ensure that a lottery is trustworthy, or could encrypt a digital letter to your long-lost half-step-brother-in-law. To make this list, maybe you use the classic coin-flip method: write down a 1 every time the coin lands heads-up and a 0 otherwise. Or maybe instead, you time the decay of the radioactive cesium that you stole from the lab. Is one of these methods better than the other; does it even matter? Yes, on both counts.
Let’s explore the principles of randomness together, and some new results from Quandela that generate certifiable randomness according to the laws of quantum mechanics.
Part 2: Generating randomness
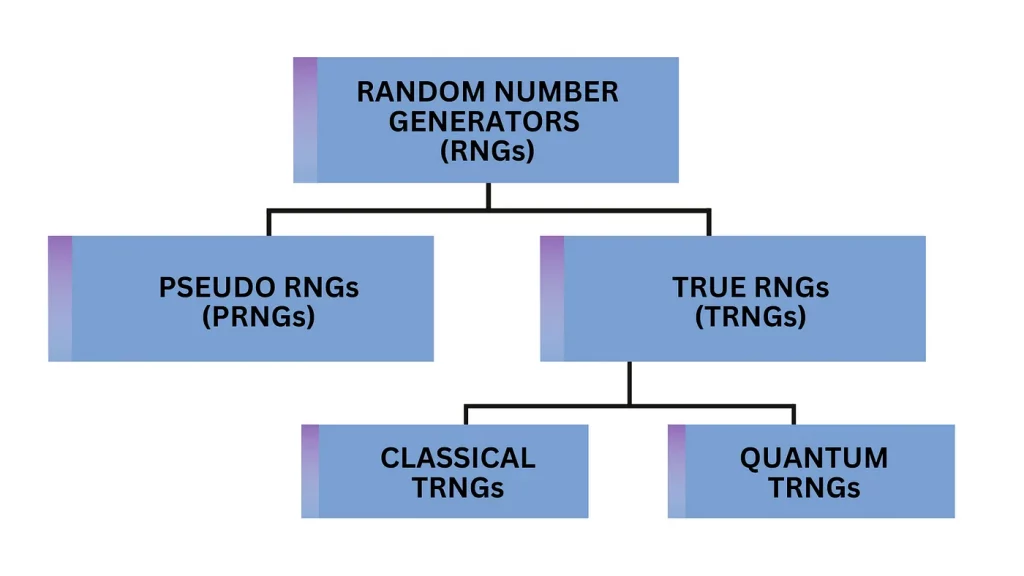
We’ve already talked about two Random-Number Generators (RNGs), the coin flip and the radioactive cesium, both of which are examples of true RNGs. That is, they rely on unpredictable physical processes (or, rather, not-easily-predictable) to make their lists of 0s and 1s. But there are many kinds of RNGs, which you can see in Fig. 1
Fig. 1: Various classes of random number generators discussed in this article.
The one programmers are probably most familiar with is pseudo-RNGs. Here, you give a random seed number to a mathematical algorithm, which uses that number to deterministically generate a longer list of numbers that look random. While this is a convenient way to generate random numbers, there is a big caveat: if someone ever gained access to your seed numbers, past or present, they could replicate all of your numbers for themselves!
Then you have true RNGs, of which there are two main kinds: classical and quantum. These are based on unpredictable physical processes. A simple example of a classical true RNG is the coin flip, but there are many more complex methods that are used in modern electronics, for example measuring thermal noise from a resistor. The Achille’s heel of classical true RNGs is that while the details of the generating process may be unknown, they are still in principle knowable. What are the implications of this? Well, if a bad guy wants to know your random numbers, they can always build a better model of your classical system for better predictions. Your classical RNG must therefore necessarily be complex.
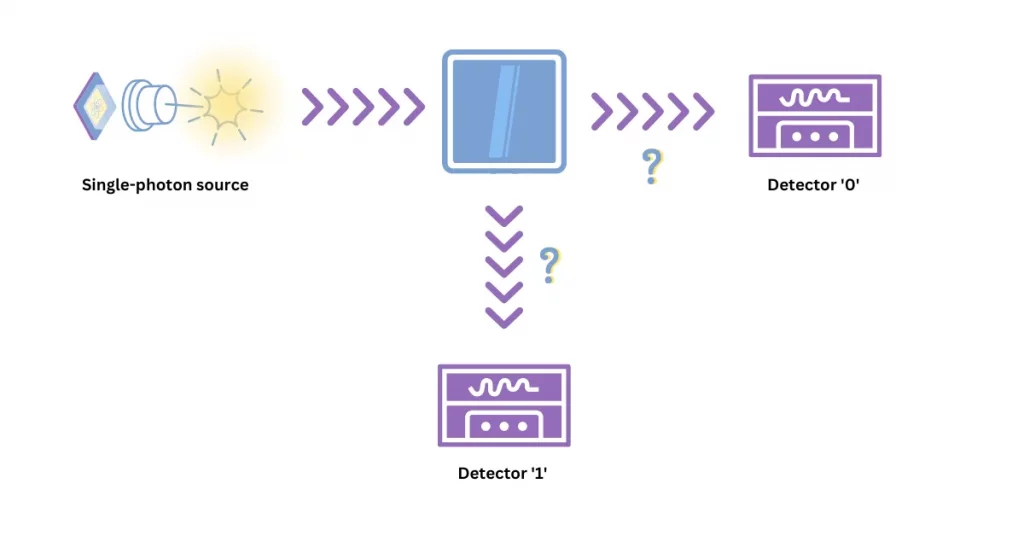
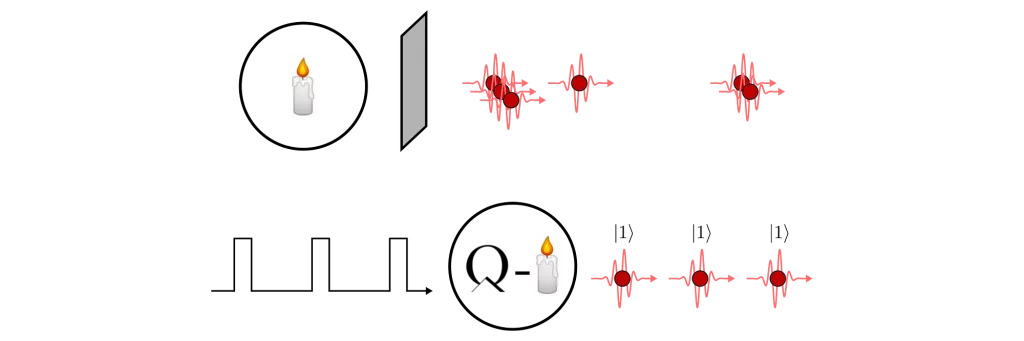
Quantum true RNGs can do better. Rather than watching our stolen cesium beta-decay, we’ll take an example from quantum optics (see Fig. 2). Here, a train of single photons is shone onto a semi-transparent mirror, which has two outputs. Because quantum mechanics is inherently unpredictable, the single photon will randomly take one of these two paths, after which it can be measured by one of two detectors, which correspond to 0 or 1. This is good at first sight, but be careful: in an ideal world, where all of the photons really are single, the beam splitter doesn’t absorb any photons, and the detectors don’t have any noise or loss, then we really do get independent and identically distributed random numbers. But this is not an ideal world, and so we call this kind of quantum RNG device-dependent because we must trust the physical engineering of the RNG. However, quantum RNGs are still a step in the right direction because we do not have to complexify them like in the classical case.
Fig. 2: An example from quantum optics of true random number generation. Single photons are shone onto a semi-transparent mirror, and they will randomly go to detector 0 or 1.
Now, we wouldn’t have given the previous example a fancy name like device-dependent quantum true random number generator if there wasn’t also such a thing as device-independent quantum RNGs — the holy grail of RNGs. The latter devices can generate and validate their own random numbers: they are certifiably random, independent of the underlying hardware. But how can we make such a thing? We use entanglement.
Essentially, if Alice and Bob share two entangled particles, and Alice measures her particle, then the state of Bob’s particle is instantly changed according to Alice’s measurement, no matter how far apart they are. This is a fundamentally quantum effect which cannot be described classically. But we have to be careful that Alice and Bob aren’t cheating. If Alice and Bob are physically too close, then we don’t know if they’re secretly sharing information to coordinate their measurements. When they’re sufficiently separated, we call this nonlocality.
So, if Alice and Bob create a pair of entangled particles, then randomly choose how to measure them, the outcomes of their measurements are quantum-certified random so long as satisfy the nonlocality condition (and a couple of other secondary conditions which are beyond the scope of this article; see Quandela’s recent publication on quantum RNGs).
Because of nonlocality, these kinds of random-number experiments tend to be big so that the measurements are far, far apart. In a world which is both obsessed with small, scalable devices and also maximum security, how can one reconcile this paradox? This is exactly the problem that researchers at Quandela have solved.
Part 3: Quandela’s contributions
They ask:
‘How can we certify randomness generation in a device-independent way with a practical small-scale device, where [Alice and Bob could cheat thanks to communication] between the physical components of the device?’
Put another way, when you have a small device that might normally allow Alice and Bob to cheat by communicating information before the other one measures their particle, can you account for this local communication somehow to still generate certified random numbers? Quandela’s protocol measures the amount of information that an eavesdropper could potentially use to fake violation of locality, and then sets a bound on how well the device should perform if it is to still produce certified random numbers. The device also periodically tests itself to validate these numbers.
And not only has Quandela derived the theory, but they’ve also demonstrated it experimentally on a two-qubit photonic chip using Quandela’s patented single-photon quantum dot source, show in Fig. 3.
Fig. 3: Quandela’s two-qubit random number generator.
If this all sounds like a big deal, that’s because it is — the technical details are all found in the recent publication, with a patent on its way!
This achievement represents a major step towards building real-world, useable quantum-certified random number generators, one more tool in Quandela’s arsenal of quantum technologies.
If you are interested to find out more about our technology, our solutions, or job opportunities, visit quandela.com.
This is part three of our series on single-photon sources. Building on our previous posts, we finally have the necessary context to discuss Quandela’s core technology and how it will accelerate the development of quantum-photonic technologies towards useful applications.
Atoms
Even though heralded photon-pair sources are a well-known technology, it does seem to be a bit of a work-around to achieve our primary goal of generating pure single-photons. The fact that they are inherently spontaneous is an issue, and we would prefer to avoid multiplexing which is resource hungry. OK then, is there another approach?
Atom-light interaction
An elegant idea comes from our knowledge of how light interacts with single quantum objects such as atoms. In this context, what we really mean by a “single quantum object” are the quantised energy levels of a bound charge particle. In a hydrogen atom for example, the electron is trapped orbiting around the much-heavier proton and it can only exist in one (or a superposition of) discrete quantum states.
Quantum states of the electron in a hydrogen atom. The electron is currently in the ground state.
When we shine a laser on an atom, we can drive transitions between two states. For example, the electron can be promoted from its ground state to a higher-energy excited state. In general, there are certain constraints that the pair of states must satisfy for transitions to occur under illumination. These are broadly called selection rules and correspond to various conservation laws that the interaction must obey.
In our case, we are interested in dipole-allowed transitions which result in strong atom-light interaction. To drive an electric dipole transition, the laser must be resonant (or near-resonant) with the energy difference separating the two states. This means that we have to tune the angular frequency of the laser ωₗₐₛₑᵣ such that the photon energy ħωₗₐₛₑᵣ is equal (or near-equal) to the difference in energy.
Rabi cycles, named after Nobel-prize winner Isidor Rabi.
When this is done, the electron starts to oscillate between the ground and excited levels, creating quantum superposition of the two states in between. This phenomenon is called Rabi flopping. If we control the exact duration of the interaction (i.e. the amount of time the laser is on) we can deterministically move the electron from the ground to the excited state, and vice-versa.
Spontaneous emission
As with spontaneous parametric down-conversion (see part 2), the vacuum fields also play an important role here. When the electron is in the excited state, it doesn’t stay there forever. The presence of vacuum fluctuations cause the electron to decay back to the ground state in a process called spontaneous emission (in fact it’s a little more complicated than that, but this is a fine description for our purposes). Spontaneous decay of the excited state is not instantaneous, and typically follows an exponential decay with lifetime T or decay rate Γ=1/T .
Additionally, there’s another property of dipole-allowed transitions which is of great interest to us. As one might have guessed from the resonant nature of the interaction (i.e. energy conservation), the full transition of the electron from the ground state to the excited state (or vice-versa) is accompanied by the absorption (or emission) of a single photon from the laser. And more importantly, spontaneous decay from the excited state to the ground state always comes with the emission of a single photon.
Two ingredient single-photon recipe.
So here we have a recipe to create a single photon. We first use a laser pulse to excite the electron to the excited state, and then we wait for the electron to decay back to the ground state by emitting a single photon.
Note however, that the laser pulse has to be short compared to the lifetime of the excited state. Re-excitation of the emitter can happen as soon as there is some probability that the electron is in the ground state. Therefore, if the laser pulse is still on when spontaneous emission has already started, there is a chance that the emitter will spontaneously emit, get re-excited and emit again. This has the undesirable effect of producing two photons within our laser pulse.
We can now see the major difference between the scheme based on spontaneous parametric down-conversion and the one based on spontaneous emission. With the latter, we can use short laser pulses to actively suppress the probability of multi-photon emission (and minimise the g⑵ ) without compromising on brightness.
The brightness is unaffected because the electron will always emit a single photon if it is completely promoted to its excited state. This is why sources based on such emitters are usually referred to as “deterministic” sources of single photons.
Collecting photons
Dipole radiation
So, can it be that simple? Well, there is one thing we haven’t considered yet: where the photons get emitted. And unfortunately for us, single-photons tend to leave the atom in every direction.
To be more precise, spontaneous emission (from a linearly-polarised dipole-allowed transition) follows the radiation pattern of an oscillating electric dipole, similar to that of a basic antenna. Recall that a radiating dipole is two opposite charges oscillating about each other on a fixed axis.
The fact that dipoles come up again here is not a coincidence. The rules of dipole-allowed transitions and dipole radiation stem from the same approximation that the wavelength of the emitted light is much greater than the physical size of the atom.
On the left, we show the electric field generated by an oscillating dipole oriented in the vertical direction. We see that, apart from the direction of the dipole, the field propagates rather isotropically, and there is no preferred direction in the horizontal plane. This is essentially because the system has rotational symmetry.
If we look far away from the dipole, we can calculate the optical intensity that is emitted in space for every direction. This graph gives us the probability per steradian that a single photon is emitted at every angle. The redder the colour, the more likely a photon will emerge in that direction.
It should be rather obvious why the above figure is bad for us. To collect all the photons into a light-guiding structure like an optical fibre, we would require an impossible system of lenses and mirrors to redirect all the emission back into the fibre.
And if we lose a large portion of the emitted photons, our deterministic source becomes a low-brightness one, limiting the scalability of our quantum protocols.
The Purcell effect
To help us collect more photons from atoms, we can rely on an amazing fact of optics: the lifetime and radiation pattern of an emitter dependon its surrounding dielectric environment, a phenomenon called the Purcell effect. In fact, the radiation pattern we have shown above is only true for an atom placed in a homogeneous medium.
You might think: “Well, that sounds trivial. If I put an optical element like a lens in front of the atom, I am guaranteed to change it’s emission pattern in some way”. And indeed you would be right, but here we are looking at something a little more subtle.
We mentioned above that spontaneous emission is caused by vacuum field fluctuations. It turns out we can engineer the strength of these fluctuations at the position of the atom to accelerate or slow down spontaneous emission in certain directions. To do this, we have to build structures around the atom which are on the scale of the emitted light’s wavelength (λ).
Let’s look at an example: the emitter placed in between two blocks of high refractive-index material (like gallium arsenide — GaAs).
The important parameter here is the Purcell factor: the ratio of the emitter’s lifetime in the structure divided by its lifetime in the bulk material (here it’s just air). As the distance between the blocks (d) decreases, the lifetime of the emitter varies widely (as quantified by the Purcell factor). What’s going on?
Optical modes
The magnitude of the vacuum field fluctuations depends on a couple of things. First, it depends on the number of solutions there are to Maxwell’s equations at the frequency of the emitter (the so-called density of optical modes). With an increasing number of available modes, there are more paths by which light can get emitted by the atom, and spontaneous emission is sped up.
Secondly, we have to consider how localised the electric field fluctuations of the modes are. An optical mode that is spread out in space does not induce strong vacuum fluctuations at one particular position. Whereas a localised mode concentrates its vacuum field where it is confined in space.
If one particular mode has larger local fluctuations than others, the atom preferentially decays by emitting light into this mode (larger fluctuations translate to high decay rates). The radiation profile is therefore changed because the emission will mostly resemble the profile of the dominant mode.
This is what we are seeing in the above experiment. As the separation between the two blocks decreases, cavity modes come in and out of resonance with the emitter. Cavities are dielectric structures which trap light using an arrangement of mirrors. Here, the cavity is formed from the reflections off the high-index material causing the light to bounce back and forth in the air.
Cavity modes only appears at the frequency of the emitter when we can approximately fit an integer number of half-wavelengths between the blocks, creating a standing-wave pattern in their electric field profile.
In our example however, we only see those modes with an integer number of full-wavelengths. This is because the other modes do not induce any electric field fluctuations exactly at the middle point between the blocks, where we placed our emitter. There is a node in their standing wave pattern. Therefore, no spontaneous emission from the atom goes into these modes, and they don’t affect its lifetime.
In contrast, modes with an integer number of full-wavelengths between the mirrors have the maximum of their fluctuations at the centre (anti-node of the standing wave). Therefore, they strongly affect the lifetime of the emitter and its radiation pattern.
Trapping light
By trapping light with mirrors, we have seen how a cavity mode can induce strong vacuum fluctuations at the position of an atom, and therefore funnel its spontaneous emission in a desired direction. It is important to note that the confinement of cavity modes not only depends on how close the mirrors are to each other, but also on how long the light stays inside the cavity. A “leaky” cavity that does not trap light for a long time also does not induce strong vacuum fluctuations.
The cavity we have studied above can only trap light in the vertical direction. We see that the modes have an infinite extent in the horizontal plane because of the continuous translational symmetry. In addition, they do a rather poor job at that. The reflectivity between air and GaAs is only about 30%, meaning that on each bounce 70% of the light is lost upwards or downwards.
So first, we could use better mirrors. A great way to build a mirror is to alternate thin layers of high and low refractive-index materials. These so-called Bragg mirrors can be engineered to have extremely high reflectivity at chosen wavelengths. This is achieved by making sure that each layer fits a quarter-wavelength of light, so that reflections of all the interfaces interfere constructively.
(1) A planar cavity with no lateral confinement. (2) & (3) A micropillar cavity with its mode confined in all 3 dimensions.
Next, we have to confine the mode in 3D. One way to do that is to curve one (or the two) Bragg mirrors to compensate for the diffraction of light inside the cavity. Our preferred method is to structure the stack of layers into micropillars. The high refractive-index contrast between the pillar and the surrounding air confines the light inside the pillar due to index-guiding (this is similar to the mechanism by which light is guided by an optical fibre).
By making these structures, we get cavity modes that are highly localised and that trap light for a long time. If an atom is placed at an anti-node of the cavity’s electric field, the probability of the emission going into the cavity mode will be much greater than that of the atom emitting in a random direction.
An emitter in free space emits photons everywhere. In a leaky cavity, the single-photons preferentially emerge in one direction.
The final piece of the puzzle is what happens to the single-photon once it has been emitted by the atom and is trapped inside the cavity. The Bragg mirrors are designed to keep the light in for a long time, so the photons will mostly leave the cavity from the sides in random directions. This defeats the point of having a cavity in the first place!
To design a good single-photon source, we have to make one mirror less reflective than the other (with less Bragg layers for example) so that the photons preferentially leave the cavity through that mirror only. This is how we achieve near-perfect directionality of the source. Finally, by placing a fibre close to the output mirror, we can then collect the emitted single-photons with high probability.
Note however, that this is a compromise. By reducing the reflectivity of one mirror, the mode of the cavity is not as long-lived, which reduces the vacuum-field fluctuations and therefore decreases the probability that the atom emits into the cavity mode in the first place. Careful engineering of the structure has to be made to strike the right balance.
Quantum dots
It is a hard technological challenge to build the microstructures for the efficient collection of photons. An even harder task is to place an atom at the exact spot where the vacuum-field fluctuations of the cavity mode are at their maximum. While this can be done with single atoms in a vacuum, this involves a very complex procedure and bulky ancillary equipment.
Trapping electrons
Another way to proceed is to find quantum emitters directly in the solid-state. In the last few decades, a number of ways have been found to isolate the quantum energy levels of single electrons inside materials. The approach that we are leveraging is that of quantum dots.
Transmission electron microscopy and electronic structure of quantum dots. At low-temperatures, only states below the Fermi energy (Ef) are occupied.
Quantum dots are small islands of low-bandgap semiconductor material, surrounded by a higher bandgap semiconductor. Because of the difference in bandgap, some electronic states can only exist inside the low-bandgap material. The confinement of electronic states to a few nanometres creates discrete quantum states in a way that is very similar to the classic particle in a box model in quantum mechanics.
This arrangement gives us access to bound electronic states very much like an atom does. That is why quantum dots are sometimes referred to as artificial atoms in the solid-state.
Quantum dots are small islands of low-bandgap semiconductor material, surrounded by a higher bandgap semiconductor. Because of the difference in bandgap, some electronic states can only exist inside the low-bandgap material. The confinement of electronic states to a few nanometres creates discrete quantum states in a way that is very similar to the classic particle in a box model in quantum mechanics.
This arrangement gives us access to bound electronic states very much like an atom does. That is why quantum dots are sometimes referred to as artificial atoms in the solid-state.
Single-photons from the relaxation of an exciton in a quantum dot.
We can then use the same procedure described above to generate single-photons from these states. In this case, we use a pulse laser to promote one electron from the highest occupied state in the conduction band of the dot to the lowest unoccupied state in its valence band.
Compared to the hydrogen atom, the absence of an electron in the valence band is more significant. This ‘hole’ acts as its own quasiparticle, and the effect of the laser pulse is to create a bound state of an electron and a hole, called an exciton (another quasiparticle). The exciton doesn’t live forever. The vacuum field fluctuations cause the electron to recombine with the hole and in doing so a single-photon is created.
Suppressing vibrations
The electronic levels are not completely isolated from the solid-state environment there are in. The most important source of noise comes from temperature: the jiggling of the atoms in the semiconductor.
Temperature affects the quantum dots in a couple of ways. First, the presence of vibrations in the crystal’s lattice adds an uncertainty in the energy difference between the electronic levels (technically, they induce decoherence of the energy levels). This has a detrimental effect on the indistinguishability of the emitted photons which will also have this added uncertainty in their frequencies.
The lattice vibration (or phonons) affecting the process of single-photon emission.
The second effect is that the emitter can emit (or absorb) vibrations of the surrounding crystal during the photon emission process. Because the vibrations carry energy, the emitted photons will again have very different frequencies from one emission event to the other, reducing indistinguishability.
The solution to this is to cool the sample to cryogenic temperatures to get rid of the vibrations inside the material. For quantum dot emitters, cooling the samples between 4K and 8K is sufficient to suppress the thermal noise. This is the realm of closed-cycle cryostats, which are much less demanding than the more complicated dilution refrigerators.
Suppressing the laser
Another important consideration for quantum emitters is how to separate the emitted photons from the laser pulses. If we cannot distinguish between the two, the single-photon output is simply drowned out by the laser noise.
Three-level system for polarization or frequency separation of the pump laser and the single-photons.
Typically, it’s very hard to completely avoid laser light reaching the output of the single-photon source. A good solution here is to use an additional energy level of our quantum emitter.
The key is to find two optical transitions which are separated in frequency (or addressed by orthogonal polarisations of light) such that we can filter out the laser (using optical filters or polarisers) from the single-photons at the output. The excited states must be connected in some way to efficiently transfer the electron to the extra state during the laser excitation.
With dots we have access to two different ways to do that. First, we can use the solid-state environment to our advantage by leveraging the coupling of the emitters to the vibrations of the crystal. By using non-resonant laser pulses, we can force the emission of an acoustic phonon to efficiently prepare an exciton.
The second option we have with quantum dots is to use two electronic states which interact with orthogonal polarizations of light. This is a particularly good method when combined with elliptical cavities.
Putting everything together
At Quandela we benefit from decades of fundamental research in quantum dot semiconductor technology. This allows us to bring all the elements together to fabricate bright sources of indistinguishable single-photons.
Importantly, we use a unique method (developed in the lab of our founders) to deterministically place single quantum-dots at the maximum of the vacuum-field fluctuations of micropillar cavities. In this way, we make the most out of the Purcell effect.
In the figure above, we show a 3D rendering of our single-photon sources. As discussed above, they consist of a quantum dot at the anti-node of a long-lived cavity mode which preferentially leaks through the top mirror towards an output fibre.
The ‘cross’ frame around the pillar cavity is there to make electrical connections to the top and bottom of the semiconductor stack. This allows us to control the electric environment of the dots and tune its emission wavelength with the Stark effect.
Scanning electron microscopy of single-photon sources by Quandela.
With the current generation of devices, we simultaneously achieve an in-fibre brightness of > 30%, a g⑵ < 0.05 and a HOM visibility > 90% (see part 1). With these state-of-the-art performances, we believe that large-scale quantum photonics applications are within reach.
A quick note on scalability
More complex applications in quantum photonics require multiple photons to arrive simultaneously on a chip. The obvious route here is to have multiple sources firing at the same time to provide single-photons in multiple input fibres.
While it is generally more difficult for remote sources to generate identical photons (i.e. with perfect HOM visibility), recent results suggest that the reproducibility of our fabrication process is the key to large-scale fabrication of identical sources.
Additionally, we can use active temporal‐to‐spatial demultiplexing to take advantage of the indistinguishability of the photons coming from the same source. This technique can be thought as the inverse of the temporal multiplexing that we saw in part 2 for spontaneous pair-sources.
Starting from a train of single-photons, we switch and delay some of the photons to get several spatial inputs. With a demultiplexer, we reduce the repetition rate of our source to achieve synchronised inputs. The n-photon coincidence rate is then given by
where (as we defined in part 1) μ is the detection efficiency, B the source efficiency and 𝜂 is the demultiplexer efficiency. R is the repetition rate of the laser pulses.
Conclusion
In this series, we have reviewed the state-of-the-art technology for producing single-photons on demand. We have explored in some detail the underlying principles of spontaneous-parametric-down-conversion and atom-like quantum emitters and highlighted their differences.
At Quandela, we feel that quantum-dot sources have great potential for the miniaturisation and scalability of optical-qubit generators. We are working hard to improve their performances and to make them accessible to a wider academic and industrial audience.
If you would like to know more about our technology please email contact@quandela.com or visit our website https://quandela.com/ . If you would like to join our mission to build the world brightest sources of optical qubits, please have a look at our job openings at https://apply.workable.com/quandela/ .
Welcome to part two of our series on single-photon sources. Here, we will discuss one possible route for single-photon generation: spontaneous photon-pair sources.
Non-linear optics
To understand spontaneous photon-pair sources we have to delve into how dielectric material react to light. Classically, light is nothing but the synchronised oscillations of electric and magnetic fields. And dielectrics are electrical insulators which can be polarised by an electric field. Let’s try to unpack these concepts.
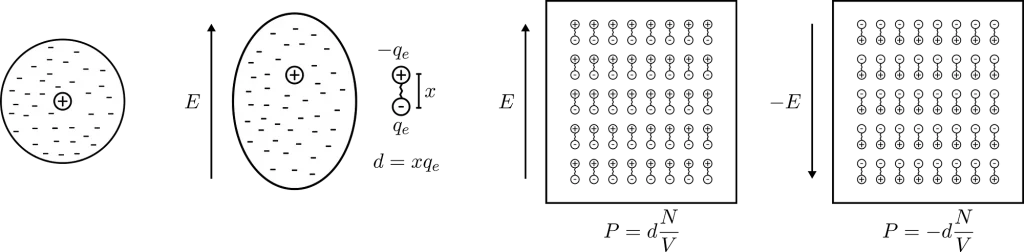
When an electric field E is applied to a dielectric material, the electrons within the material’s atoms are pulled away from their respective nuclei but without being able to escape (because dielectric materials are insulators). This creates many dipoles (pairs of positive and negative charges separated by a small distance) and we say that the material is polarised.
The macroscopic strength of these dipoles is described by the polarisation density P which is given by P = x * qₑ * N/V where x is the separation between to charges, qₑ is the negative charge (assuming the charges are opposite but equal in magnitude) and N/V is the density of dipoles (number of dipoles per unit volume).
Polarisation of an atom (left) and of a dielectric material (right) with an electric field.
Let’s now assume we have a perfectly monochromatic laser beam oscillating with an angular frequency ω and traveling through the dielectric. In complex notation we can write this as
where c.c. is the complex conjugate of the term in front. In response to the oscillating electric field, the electrons and nuclei also start to oscillate, and we get a bunch of oscillating dipoles which in turn lead to a macroscopic polarisation density P(t) that oscillates. It is typically assumed that P(t) depends linearly on the external electric field, so that
where the constant of proportionality ꭓ⑴ is known as the linear susceptibility of the material and 𝜖₀ is the permittivity of free space. The important take-away here is that the dipoles oscillate at the same frequency than the laser.
What’s more, oscillating dipoles are nothing but accelerating charges which themselves emit electromagnetic radiation. It turns out that the dipoles act as a source of light Eₚₒₗ(t) which oscillates at the same frequency as P(t). This new field then gets added to the external driving field.
We therefore have the following string of cause-and-effect Eₗₐₛₑᵣ(t) → P(t) → Eₚₒₗ(t) which produces the output field Eₗₐₛₑᵣ(t)+Eₚₒₗ(t) where the two components oscillate at the same frequency.
In some dielectrics and at high driving power (large Eₗₐₛₑᵣ), the linear relationship between Eₗₐₛₑᵣ(t) and P(t) breaks down. We now enter the nonlinear regime where the relationship is better approximated by adding extra terms in the power series expansion like so
Note that ꭓ⑵ and ꭓ⑶ are typically a LOT smaller than ꭓ⑴ in magnitude. Focusing on the ꭓ⑵ non-linearity and expanding the squared term we get
In this regime, the dipoles not only oscillate at the frequency of the driving laser but also pick up another frequency component at 2ω. The result is that light is emitted at a different frequency than what had been sent in the material. In this case, we get second-harmonic generation.
So what is happening at the level of the photons? Recall that the energy of a photon is given by ħω where ħ is the reduced Planck’s constant. Here we’re assuming that the material is transparent (that it does not absorb energy), so in order to conserve energy two laser photons at frequency ω must be absorbed to generate a photon at frequency 2ω.
A ꭓ⑵ dielectric pumped with a single laser (left) and two lasers at different frequencies (right).
Another interesting thing happens when we drive the dielectric material with two laser beams at different frequencies:
Again, focusing on the ꭓ⑵ non-linearity and expanding the squared term, we get terms that oscillate at frequencies ω₁+ω₂ and ω₂-ω₁ (assuming ω₂>ω₁). This is called sum- and difference-frequency generation. Sum-frequency generation is easily understood as one photon from each driving field being absorbed to produce a photon at ω₁+ω₂.
Difference-frequency generation is a little more interesting. During this process, one photon at the pump frequency ω₂ is absorbed and two photons are emitted, one at the driving frequency ω₁ (the signal photon) and the other at ω₂-ω₁ (the idler photon).
Spontaneous parametric down‑conversion
If we attenuated the signal field (ω₁) down to zero, we would not expect any difference-frequency generation to occur. However, the electromagnetic vacuum is not completely empty and at the quantum level there are vacuum fluctuations. These fluctuations correspond to the momentary appearance of particles (in our case photons) out of empty space, as allowed by the uncertainty principle.
It turns out that vacuum fluctuations cause difference-frequency generation in ꭓ⑵ dielectrics without the presence of a signal field. This process is called spontaneous parametric down‑conversion and leads to one photon in the pump field being absorbed and a photon pair being emitted. Parametric just means that no energy is absorbed by the material, and the process is spontaneous because we cannot control when and where in the crystal the down‑conversion will occur (like all the other nonlinear processes).
Spontaneous parametric down‑conversion in a ꭓ⑵ material.
Because we don’t have a second reference frequency any more, it’s fair to ask at what frequencies the photons will emerge. In addition to respecting conservation of energy, the photons involved in the down‑conversion process must also obey conservation of momentum. The momentum of a photon is given by ħkwhere |k|= n(ω) * ω / c is called the wavevector and it depends on the material’s refractive index n at the frequency of the photon (c is the speed of light).
Momentum conservation dictates that k(ωₚ)=k(ωₛ)+k(ωᵢ) (where the subscripts p, s and i correspond to the pump, signal and idler photons respectively), and because of material dispersion and birefringence this condition is only satisfied for certain frequencies, directions and polarisation of the photons (and they need not be the same for the signal and idler).
Conservation of momentum is also referred to more broadly as phase-matching. In general, the properties of the signal and idler photons satisfying energy and momentum conservation are usually not the ones we want. To solve this, we must engineer the nonlinear material and the setup to achieve phase-matching for the correct output frequencies. This can be done by birefringent phase-matching, by engineering the dispersion profiles of optical modes and with quasi-phase-matching.
Materials with large ꭓ⑵ coefficients required for spontaneous parametric down‑conversion are usually rather exotic. Common choices are lithium niobate (LiNbO3), potassium titanyl phosphate (KTiOPO4) or aluminum nitride (AlN).
It is also possible to use higher non-linear coefficients to achieve a similar effect. The other popular choice is spontaneous four-wave-mixing in ꭓ⑶ materials. More common materials, like silicon, have large ꭓ⑶ coefficient which makes this process an appealing alternative.
Spontaneous photon-pair sources as emitters of single photons
The discussion so far has been quite removed from the topic of single-photon sources. In this section we finally answer why spontaneous photon-pair sources can be useful in that regard.
Two-mode squeezed-vacuum
First, let’s recall (see part 1 of the series) that sources of single photons have to be triggered. By exciting a ꭓ⑵ dielectric with a continuous laser, spontaneous parametric down‑conversion does not allow us to control the emission time of a photon pair.
A better alternative is to restrict the emission to time slots defined by laser pulses. The nonlinear process can only take place when the laser is “on” and that acts as our trigger. However, we cannot completely control whether a photon-pair is emitted within one laser pulse or if we get multiple pairs.
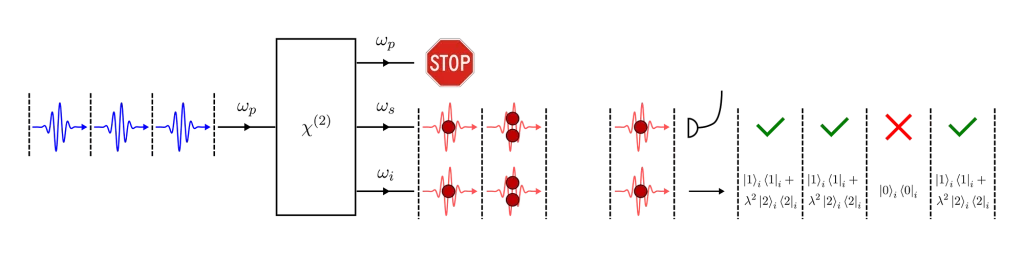
In fact, if we can separate the down-converted photon from the pump light, the photon-number state that we get in each pulse is (ignoring the spectral, momentum and polarization degrees of freedom)
This state is called the two-mode squeezed-vacuum state and the parameter λ (called the squeezing parameter) is a number between 0 and 1 which quantifies the strength of the interaction. λ depends on the ꭓ⑵ nonlinearity, the interaction length and the laser power. Note that the two-mode squeezed-vacuum state is an entangled state in photon number.
Assuming that λ is small, we can approximate the emitted state as
From this, we can directly calculate the probabilities of getting one or two pairs in the time slot defined by a laser pulse. We have to square the amplitudes to get probabilities, so P(1 pair)≈λ² and P(2 pairs)≈λ⁴.
A pulsed nonlinear photon-pair source.
If we separated the signal and idler photons, could we use either of them as a single-photon state? Well, we are not off to a great start because we have some probability of having more than one photon-pair per laser pulse. In fact, if we completely ignored one of the outputs of the down‑conversion process (say the signal photons), the idler photons would have
Remember that a single-photon source needs a g⑵ as close to 0 as possible to avoid errors in our quantum protocols. A g⑵ equal to 2 is bad. In fact, it’s worse than if we had just used strongly attenuated laser pulses directly, which have g⑵=1.
Heralding
This can be redeemed if we use the photon-number entanglement in the two-mode squeezed-vacuum state. The trick is to monitor one of the outputs (say the signal) and record which output pulses have one or more photons. If we detect signal photons in a particular time slot, we now know that there is at least one photon in the idler path.
So, conditioned on the detection of a signal photon (or photons), the state of the idler collapses to the mixed state
And there we have it. By heralding the presence of idler photons with the signal photons, we get a state that approximates a single-photon state asymptomatically better as λ² tends to zero.
However, recall that the probability of getting a single-pair per pulse is also related to λ² (in fact it is equal to λ²) . This is an important compromise we have to make with spontaneous photon-pair sources: we have to keep the brightness of the source low in order for the single-photon purity to be high. It’s a trade-off between scalability and algorithmic errors. For example, if we wanted P(1) to be 10%, then g⑵=0.2 and that’s quite high for a single-photon source.
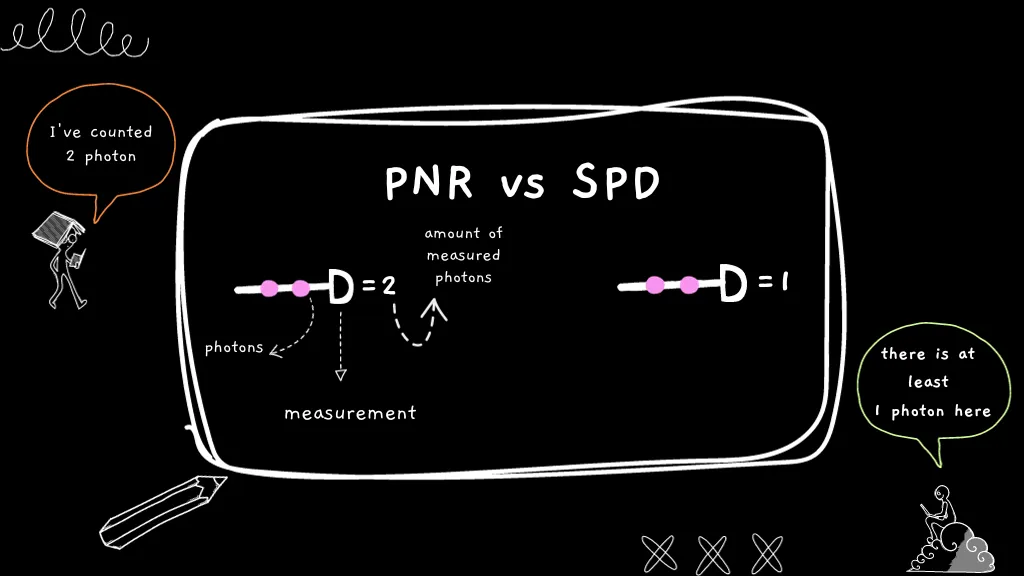
Note that this can be improved with the use of photon-number resolving detectors, which not only measure if there are photons but also how many. By heralding only the single-photon events in the signal paths (and rejected the vacuum and multi-photon components), we can decrease the g⑵. Even so, the statistics of the two-mode squeezed-vacuum state as such that the theoretical limit for brightness is 25%.
Spectral purity
Heralding is a great way to turn spontaneous photon pair sources into single-photon sources. However, it also creates additional constraints on the nonlinear process. Let’s focus on the frequencies of the emitted photon pair. In general, the emitted state is given by
where f(ωₛ, ωᵢ) is called the joint-spectral-amplitude. If f(ωₛ, ωᵢ) is not factorable — i.e. f(ωₛ, ωᵢ)≠ f(ωₛ)*f(ωᵢ) — the photons are entangled in frequency and measuring the signal photon collapses the idler to a mixed state, generally written
Mixed states in frequency are not a problem for photon purity. A single-photon, regardless of its frequency state, will only be measured at one output of a beam-splitter, and therefore has g⑵=0 (see part 1). However, it is bad for its Hong–Ou–Mandel visibility. A mixed state essentially means we have classical probabilities pₙ of getting different quantum states every time. And distinguishable states will not produce perfect interference on a beam-splitter (again, see part 1). In general, the detection of the signal photon must teach us nothing about the state of the idler photon except for its presence.
To have a spectrally-pure idler state, we have to work harder to engineer a factorable joint-spectral-amplitude. This can be done with group-velocity matching and apodization of the joint spectral amplitude by engineering the profile of the nonlinear medium. Another good method is to further engineer waveguide modes and using long interaction lengths.
Failing to produce a factorable spectrum, we can always filter the output photons to reject all possible frequency states but one. While this approach improves spectral purity and therefore indistinguishability, it comes at the cost of reducing the brightness of the source and that compromises its scalability even more.
Multiplexing
The balance between brightness and single-photon purity seems to be a major hurdle for spontaneous photon-pair sources. Is this the end of the story? No, because we can improve the efficiency of these sources by multiplexing.
At its core, multiplexing is a simple idea. Instead of using just one time-bin of one photon-pair source, we combine multiple sources (spatial multiplexing) or incorporate several time-bins of the same source (temporal multiplexing) to produce a better single-photon source. We consume more resources for better performance. Let’s quickly talk about both options.
Spatial Multiplexing
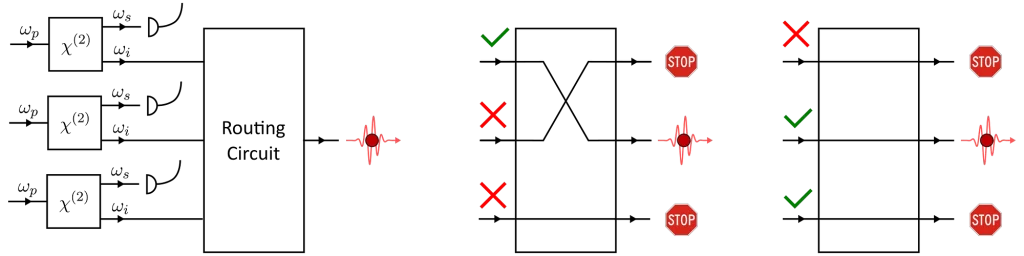
With spatial multiplexing, we first have to build a number of identical photon-pair sources. It is important that all the heralded single-photon outputs are the same or the indistinguishability of the multiplexed source will suffer.
Once that’s done, the output of the sources are connected to a reconfigurable routing-circuit (a multiplexer). All the sources are then pumped simultaneously with laser pulses and we monitor the emission of signal photons. We then pick one of the sources which has fired and route its now-heralded idler photon to the output of the circuit.
Spatial multiplexing with a reconfigurable routing circuit.
Because we have multiple sources working together, the probability that at least one fires can be a lot greater that the brightness of the individual sources. In fact, assuming a perfect routing circuit the brightness is improved by
where B₁ is the brightness of the sources and N is the number of sources hooked-up to the routing circuit.
Things now look at lot better, but we do have to consume a lot of resources. Say we want a source with g⑵=0.05 (that’s not bad for the state-of-art), then B₁ ≅ P(1) = 2.5% and we need at least 15 sources for a final brightness of 30% (28 for 50% and 91 for 90%).
Temporal Multiplexing
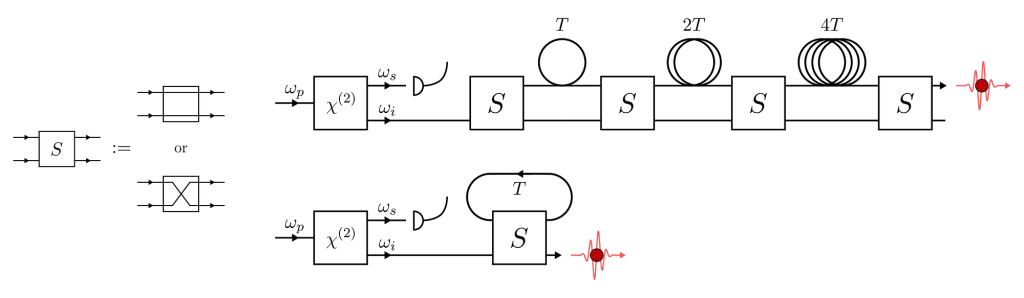
The other variant of this technique is temporal multiplexing. Here, we use contiguous time-bins of the same source (recall that we pump the sources at regular time intervals). We simply wait for the source to fire in one of the time-bins and delay the heralded idler-photon accordingly so that it leaves the circuit in a known time-bin.
Temporal multiplexing based on (1) a network of switches and (2) on a storage loop.
The overall effect is the same as for spatial multiplexing but N is now the number of time-bins that we use. One key advantage of temporal multiplexing is that sequentially emitted photons of the same source are usually more similar than those emitted by different sources, which helps with indistinguishability. The price we pay however is a decrease in the repetition rate of our source which goes from R to R / N.
Repetition rates are important in quantum photonics because experiments are usually probabilistic. We typically known when a particular run has succeeded but we could wait a while for that to happen. The ability to perform the experiment as often as possible is therefore desirable. This is what we are sacrificing with time-multiplexing.
We could also have anything in between full-temporal and full-spatial multiplexing depending on the scarcity of our two resources (experiment time vs number of sources).
Outlook
As can be seen in figures above, multiplexing can be wasteful. As we add more sources (or time-bins) to boost the brightness, we also increase the probability that two or more sources fire in the same multiplexing circuit. Unfortunately, we have to discard these photons because trying to route them to a second exit (or time-bin) will just add complexity and result in an additional source which has a poor brightness.
One interesting idea to improve this is that of relative multiplexing. In this scheme, we do not force the sources to always emit in the same exits or time-bins. Instead, we correct the relative distance (in space or in time) between photons that have been heralded. By using more of the emitted photons, we can reduce hardware complexity while improving coincidence counts.
It must be said however that multiplexing relies on the ability to integrate high-performing photonic components at scale. To implement a routing circuit, we must have access to optical switches, delay lines, single-photon detectors, fast electronics, etc… At present, photonic components can be lossy and/or slow to operate. This limits the performance of multiplexing, and we have to use even more hardware to reach the required improvement in brightness.
Summary
In summary, we have looked at how spontaneous photon-pair sources can generate single photons. We have seen how these sources are probabilistic, in the sense that we cannot completely eliminate the probability of multi-photon emission. In addition, it is only when the presence of one photon is heralded by the detection of the other that these sources become useful for single-photon generation.
We also described how the brightness of these heralded sources has to be kept low in order for the purity of the emission to be high. This can be remedied by multiplexing, but at the cost of multiplying the number of components, and therefore limiting the scalability in the long run.
Heralded photon-pair sources are very much still an active and ongoing topic of research, both theoretically and experimentally. An up-to-date review of the topic can be found here.
Next up
In the next post we will discuss a different approach to creating single-photons using deterministic quantum emitters. Compared to heralded pair-sources, deterministic sources have taken a longer time to mature and they now form the core of Quandela’s technology.
In the span of twenty years, we have witnessed an extraordinary emergence of quantum information technologies — the beginning of what some have called the second quantum revolution. Technology that was once the exclusive playground of scientists is now becoming accessible to a broad range of end-users.
This is good news because progress can be best sustained when the enabling technology is readily available to the broader research and development community. In the quantum realm, the manipulation of isolated quantum objects (atoms, electrons, photons, etc.) and control over their unique properties (entanglement, quantum superposition, non-locality, etc.) is becoming increasingly accessible owing to the development of new products.
To support the growing quantum ecosystem, Quandela is developing and commercialising sources of optical qubits based on single photons. These quantum light sources are crucial building-blocks for optical quantum technologies. To give some examples, they can enable truly-random number generation, enhanced imaging and sensing methods, secure quantum communication and scalable quantum computing.
Quandela offers the brightest single-photon sources available on the market to help researchers and businesses unlock useful quantum applications.
In this post, we will first approach single-photon sources from a conceptual level so that we can identify and understand their key properties. Then we will go on to explain some of the various performance metrics often quoted in the literature. This is important for anyone wishing to compare different kinds of photon source.
Desiderata
First let’s discuss some key properties to keep in mind when assessing single-photon sources.
Property #1: Single-Photon Purity
As the name suggests, we expect a single-photon device to produce one, and only one, particle of light at a time. This is very important because the presence of additional photons leads to errors in quantum protocols that are designed to work with precise numbers of photons.
Purity is a much harder requirement to fulfill than one might imagine. For example, we cannot build a good single-photon source by simply dimming a laser or a candle. Even if a laser beam is attenuated to the point where there is on average much less than one photon at any given time interval, the statistics are such that there is still an unacceptable probability of having more than one. So a true single-photon source must actively suppress the probability of multi-photon emission, while maximizing the probability of having just one.
An attenuated candle versus a true single-photon source.
Property #2: Photons-on-Demand
Another important requirement is that the source must be triggered. Advanced quantum-photonic protocols rely on interference effects between two photons, which typically occur on a beam-splitter (a semi-reflective mirror). To interfere, photons must arrive at the beam-splitter at the same time and that requires synchronisation. We must therefore control the emission time of the photons with a trigger.
Typically, single-photon sources may be triggered by a pulsed laser that stimulates the emission of single-photons at precise time intervals.
Property #3: Brightness
More than requiring photons on-demand, we wish for a high probability that the source emits once we do pull the trigger. This property is what is known as brightness.
It is obvious that ending up with no photons is not very useful. But obtaining a high brightness is perhaps the most difficult challenge to address, mostly because photons are very easy to lose. And for certain sources, brightness is a trade-off against a higher probability of multi-photon emissions.
A single-photon source with imperfect brightness.
Source brightness is crucial for the scalability of optical quantum technologies, since differences in the brightness have an exponential effect on performance as we increase the complexity of our protocols by adding more sources to them. Therefore even small gains in brightness can have drastic improvements for experiments with a large number of sources.
Property #4: Indistinguishability
On the topic of interference, it turns out that for two photons interfere they should ideally be completely identical to one another in all degrees of freedom. These includes polarisation, as well as spectral and spatial envelopes. This indistinguishability condition puts harsh constraints on the sources. For two photons to be exactly identical, the emission process must itself be precisely reproducible.
A single-photon source with imperfect indistinguishability.
Metrics
Now let’s see how we can put some numbers to the properties discussed above.
Purity
An important tool for assessing single photon purity is the second-order correlation function g⑵. Correlation functions are used to characterise the statistical and coherence properties of light. While a full treatment requires more space than a blog post, a first order approximation of g⑵ for high-performing triggered source is g⑵ ≈ 2 P(2) / P(1)² where P(n) is the probability of having n photons per triggering event. So a g⑵ measurement gives us a good idea of the probability that a source malfunctions by emitting two photons.
[Note that strictly speaking P(1) differs from the brightness B because most detectors only register the presence of photons but not the number of them. To complicate matters, however, some papers ignore this distinction and define B as P(1).]
But why use this metric instead of directly quoting the probabilities P(1) and P(2), etc.? Well, it turns out that this first order approximation of g⑵ can be measured in the lab with a rather simple apparatus, shown below:
A g⑵ measurement with a Hanbury-Brown-Twiss interferometer.
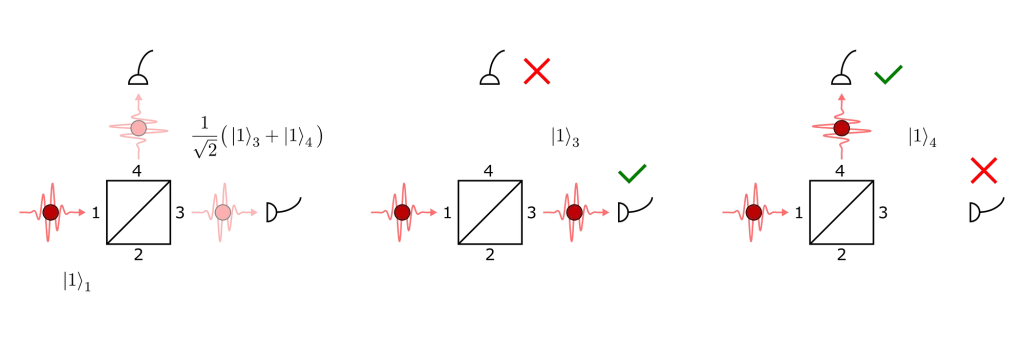
The experiment consists of sending a single photon to a beam-splitter. The action of the beam-splitter is to evenly split the photon’s wavefunction into a superposition of two distinct paths. If we observe the photon at one detector, the wavefunction collapses into the corresponding branch of the superposition and no photon is detected on the other path. So for single photons we should never observe coincidence events at the two detectors.
But let’s suppose the source has less than perfect purity and see what happens if two photons arrive at the beam-splitter:
A g⑵ measurement with 2 incident photons.
In this case, the wavefunction contains a term in which one photon exits in each path. Half of the time the wavefunction collapses to this branch and we can expect both detectors to fire.
Suppose we are working with a good source which is triggered. We observe that the probability per pulse of detecting a photon at one detector is C₁, and that the probability per pulse of having both detectors firing simultaneously is C₂ . Then to a good first approximationg⑵ ≈ C₂/(C₁)². For perfectly pure single-photon emissions there would be no coincidence events, C₂ = 0, and we would find g⑵ = 0 as expected. In practice the aim is for this figure to be as low as possible.
The result of a g⑵ measurement.
Above we show an example of a g⑵ measurement done in our labs. Here, we trigger a single-photon source with a constant repetition rate and we send the outputs of the two single-photon detectors to a coincidence time-correlator. The correlator’s job is to measure the time delay between a photon arriving on one of the detectors and the next photon arriving on the other detector. We collect many such time differences and plot them in a histogram.
In this histogram we can clearly see the repetition rate of our source, as photons emitted in different pulses can trigger both detectors albeit with a time delay. However, we see very little coincidences around zero time-delay which is the quantum signature of our single-photon source.
Brightness
Typical sources are triggered at a constant repetition rate R (number of triggering events per unit of time). With a source of brightness B (a probability lying between 0 and 1) we would end up with a single-photon count rate G = B * R .
Often, the count rate is measured at the output of a single-mode fibre which acts as a “wire” for photonic technology. So knowing the repetition and count rates would allow us to infer the brightness.
Knowing repetition and count rates we can infer source brightness.
However, detecting photons is also an imperfect process. Although single-photon detectors are a relatively mature technology, there still is a small probability that the detector does not register the presence of a photon even when one is present. For state-of-the-art detectors, the detection efficiency μ can be very close to 1 (detectors for which μ > 0.95 already exist).
Therefore our detected count rate is D = μ * B * R . So if we have the detected count rate, detector efficiency and repetition rate, it is then easy to deduce the brightness of a source.
But what if we wanted two photons in our experiment? Then we have a two-photon coincidence rate D₂ = (μ * B)² * R , as we have to multiply the probabilities that two sources successfully emit a photon and that two detectors register the emission.
More generally, we have an n-photon coincidence rate Dₙ = (μ * B)ⁿ * R . The term (μ * B)ⁿ decays exponentially with increasing number of sources. It is therefore crucial to have B as close to 1 as possible, and incremental improvements of B lead to huge gains in multi-photon coincidence rates.
Indistinguishability
Finally, we need a number to quantify the degree of similarity between photons. As we mentioned before, this is critical for building complex protocols based on photon interference. Photon indistinguishability is typically measured by a Hong–Ou–Mandel interference experiment.
The action of a beam splitter for one incident photon (left and centre). Hong–Ou–Mandel interference may occur when one photon arrives to each port of the beam splitter (right).
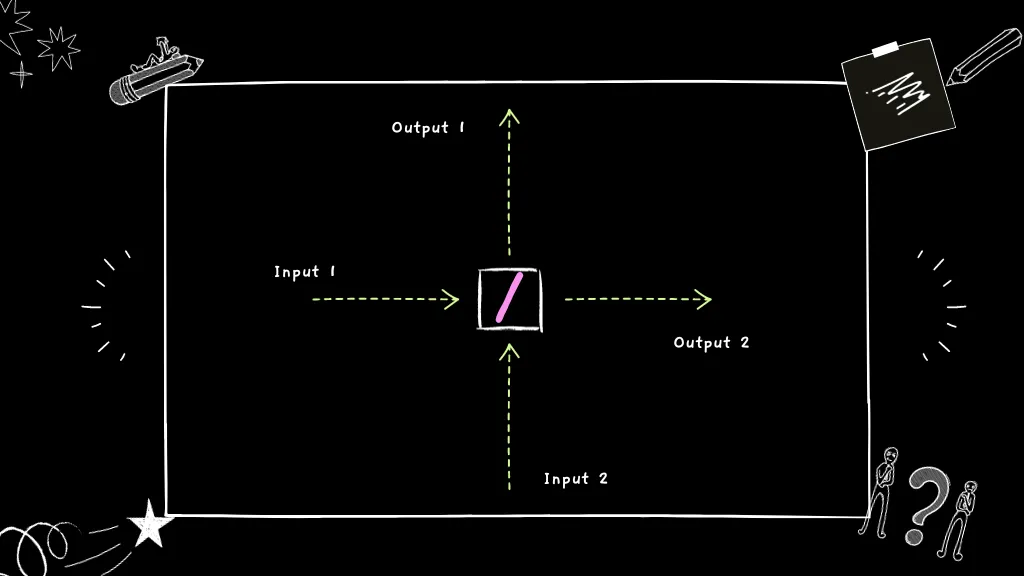
In this setup, two photons arrive at the same time via different ports of the beam-splitter. To see what happens we must first understand the full action of the beam-splitter.
Notice that the beam-splitter acts slightly differently on a photon entering by port 1 than it does on a photon entering by port 2. A minus sign appears for the reflected term of the wavefunction for a photon that entered through port 2. This so-called Stokes relation is a consequence of the time-reversal symmetry of the Maxwell equations (for lossless materials).
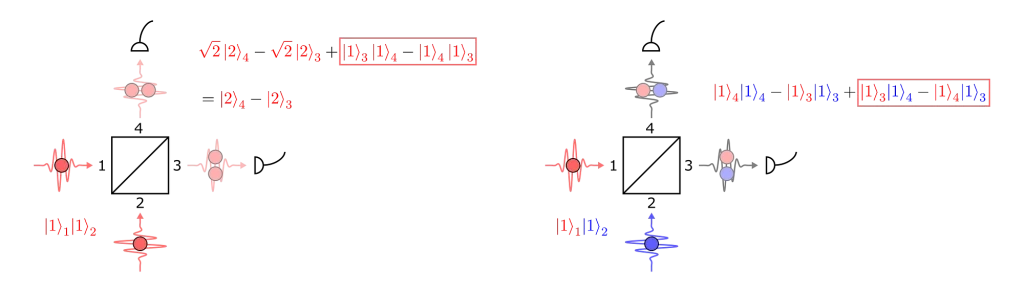
If we expand the output state in the case that a photon enters via each port, we find:
Hong–Ou–Mandel interference for indistinguishable and distinguishable photons.
Here we have separated the cases where the input photons are identical or different (after all this is what we are trying to measure).
If we have indistinguishable photons, then apart from having opposite signs there is no way to distinguish the final two terms… and their probability amplitudes cancel out! We are therefore left with an entangled state, which gives zero probability of measuring coincidences between the two detectors.
If on the other hand the two photons are distinguishable, then there is not a total cancellation between final terms, and we do observe coincidences.
So the coincidence rate in this experiment indicates how distinguishable the photons are. Usually it is simpler to speak in terms of the Hong–Ou–Mandel (HOM) visibility Vₕₒₘ, which essentially corresponds to the non-coincidence rate, and which indicates how indistinguishable the photons are.
A low number of coincidences means a high Vₕₒₘ, and Vₕₒₘ is equal to 1 only if we see no coincidences at all. For complex quantum protocols to work without being overwhelmed by errors, we should aim to have Vₕₒₘ as close as possible to 1.
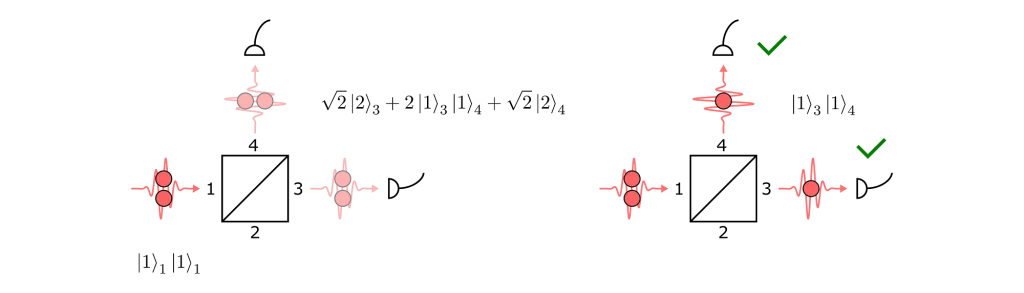
It is also important to mention that the HOM visibility can be corrupted by the presence of more than one photon in the input ports. For example, consider the following scenario:
A Hong–Ou–Mandel interferometer with multiple photons.
With an extra photon in port 1, we would get a state where coincidences are again possible. So even if a source emitted perfectly identical photons but was not perfectly pure — i.e. had some probability of emitting two at a time (g⑵>0) — then we would not measure a perfect HOM visibility.
When trying to understand why a source doesn’t have Vₕₒₘ=1 it is usually a good idea to separate out contributions due to impurity from contributions due to distinguishability. In the literature, therefore, we often find values for the corrected HOM visibility. The correction is so that we only take account of the contributions due to distinguishability.
The result of a HOM interference measurement.
Here is the result of an HOM interference measurement with one of our triggered sources. Here we precisely delay every other photon (approximately) such that two photons of the same source arrive at the beam-splitter at the same time. We then use the same coincidence correlator as for the g⑵ measurement to build up the histogram.
Again we see the repetition rate of the source as photons which do not arrive at the same time on the beam-splitter do not interfere. At zero time-delay, we do not see many coincidences which is the sign that our photons have bunched together at the output of the beam-splitter.
Summing Up
In conclusion, we have looked at the three key features of a single-photon sources: single-photon purity, indistinguishability, and brightness, and we have introduced respective metrics for assessing these: the g⑵ correlation function, the brightness as inferred from various count rates, and the HOM visibility Vₕₒₘ.
So where do we currently stand in terms of these performances? As we will see in the next posts, there are two main technologies able to produce high quality single-photons: quantum-dots in micro-cavities and spontaneous optical frequency down-conversion. Here is a rough map of the progress being made towards the ideal single-photon source:
To Be Continued
In the next post in this series we will introduce one of the technologies that has been developed to create single photons: heralded photon-pair sources with active multiplexing.
Quantum computing is a computational paradigm which encodes information into quantum systems called qubits. These qubits are manipulated using superposition and entanglement to achieve a computational advantage over classical computers. In particular, photonic qubits are one of the most promising quantum-computer technologies [1], with billions invested across the world. As the field continues to evolve quickly, the need to efficiently simulate the calculations performed by quantum circuits becomes evermore pressing.
Perceval, the software layer of Quandela’s full-stack quantum computer, allows you to simulate quantum circuits, their outputs, and to write and run quantum algorithms. The simulator includes several backends, each tailored to the different kinds of algorithms you may be interested in running [2]. Here, we’ll be learning about Perceval’s Strong Linear Optical Simulation (SLOS) backend, which allows us to time-efficiently simulate the output distribution of linear optical quantum circuits, with applications ranging from quantum machine learning to graph optimization [3].
Part 2: Why SLOS?
First, what is the difference between a strong and a weak simulation? Consider the simple example of rolling a die, where we want to know the probability of its landing on each face. There are two options: roll the die many times and write down the number of times each face turns up, or write down the precise probability that each face appears based on physical knowledge we have about the die (e.g. number of faces, shape of die). The first case of rolling the die many times is called a weak simulation, because we’re learning about a probability distribution by sampling from it, one trial at a time. The second case of writing down the precise probabilities is called strong simulation, because we have fully characterized the behavior of the die without sampling.
Now imagine that instead of a die, you had a photonic circuit like the one shown in Fig. 1, which includes indistinguishable photons through modes.
Figure 1
The output distribution is proportional to the permanent:
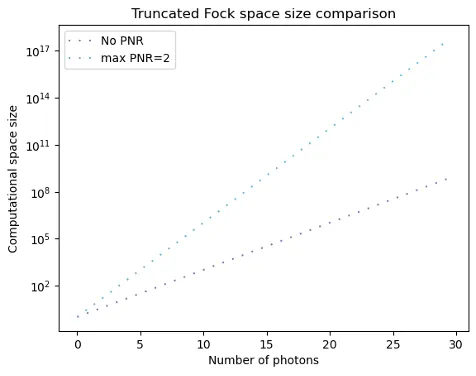
Using SLOS, we can improve on the complexity of brute-force algorithms, which calculate each output state individually, by an exponential factor of 2ⁿ. SLOS computes several inputs and outputs directly, with the time-scaling 𝒪(nMₙ), where Mₙ = C(n+m-1, m-1) is the binomial coefficient.
Part 3: SLOS_full and SLOS_gen
Perceval includes two versions of SLOS: SLOS_full, which iteratively calculates the full output distribution, and SLOS_gen, which recursively calculates the output distribution given some constraints. The mathematical key to both of these algorithms is understanding how we can efficiently decompose
where pₙ is the position of each photon that is created. For k < n-1 photons, we can add one more photon to our state as
Finally, we concatenate this product:
More simply, SLOS_full calculates and stores the coefficients of a state with photons, then extrapolates to the next state of photons — the specific algorithm is given in [3]. The complexity of SLOS_full is that given a state with photons, you have ways to put in the photon:
which is linear in the number of states!
But suppose you’re interested in only a few of the output modes, common for algorithms which rely on heralding or post-selection. SLOS_gen is the solution. This version of SLOS introduces a mask to filter the states at each step of the computation: we compute the coefficients of a full k-photon state, then we apply the mask so that we obtain only the k-1 -photon states that we’re interested in, then we compute the now-reduced k-photon coefficients and continue. While this algorithm does introduce a memory overhead because it is recursive, the average complexity still scales as 𝒪(n2ⁿ).
Part 4: Complexity vs. Memory
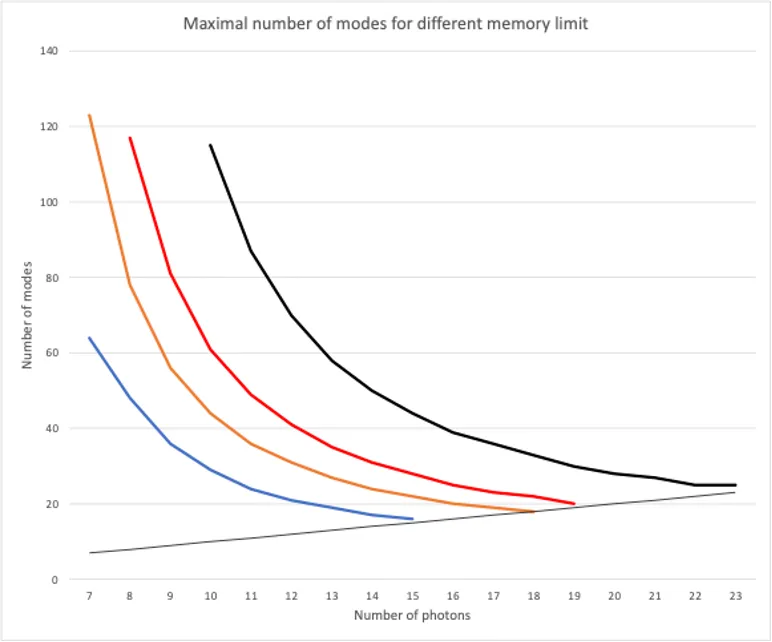
SLOS exponentially outperforms other state-of-the-art approaches, with the tradeoff being that it requires a large memory. The memory requirement of SLOS_full is 𝒪(Mₙ); for n = m = 12, M₁₂ = 1.35 × 10⁶.
The memory complexity of SLOS_gen is difficult to calculate due to state redundancy, but for a single input and output, there are C(n, n/2) coefficients to be stored. To visualize these memory constraints for typical computers, we show the maximum state size allowed for a given memory in Fig. 2 — the maximum number of photons and modes that a laptop can practically calculate is ~12.
Fig. 2. The maximum-achievable performance of SLOS running on a personal laptop (blue; 8Gb memory), and 256Gb (orange), 4Tb (red), and 1Pb (black). Image reproduced from [3].
Part 5: SLOS in action!
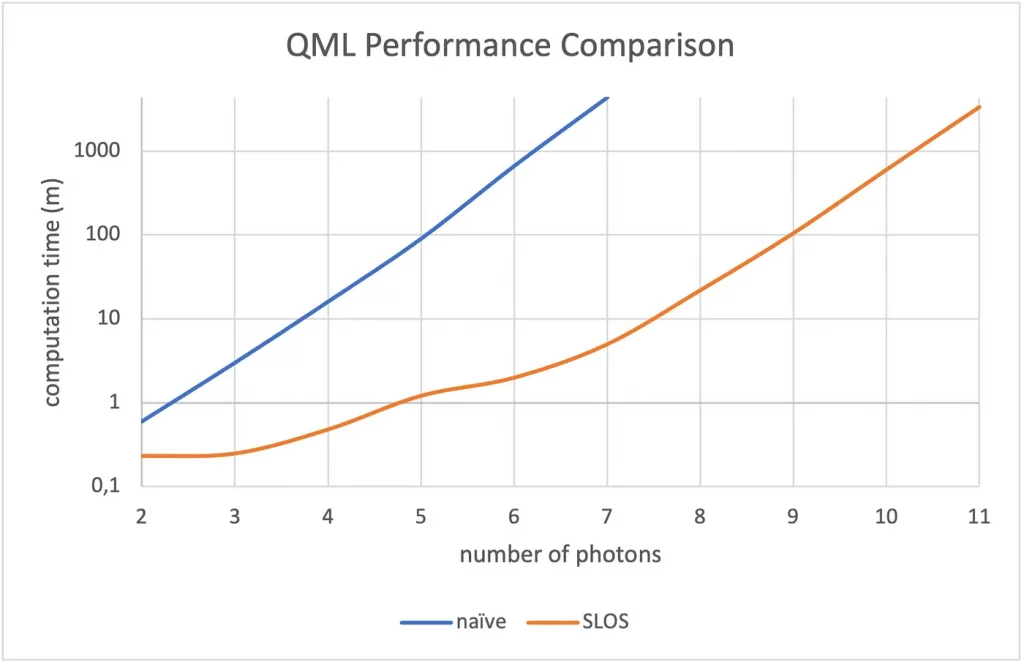
Let’s see how SLOS performs on a typical quantum machine learning application, where we want to train a quantum circuit to approximate the solution of a differential equation [7]. This requires repeatedly calculating the full output distribution, optimizing the circuit configuration each time. The algorithm converges in 200 to 400 iterations, each with thousands of full-distribution calculations! When we compare the performance of the traditional approach used in the original research versus SLOS, we see that the number of calculable photons is improved from 6 to 10 (see Fig. 3). Put another way, if you are interested in using 6 photons for the simulation, the SLOS optimization takes only 2 minutes, a factor-330 time improvement over the original method.
Fig. 3. The SLOS advantage on a typical quantum machine learning application. SLOS performs exponentially better than the naïve approach when calculating the full output distribution, by a factor of 2n.
Part 6: Where and how to use SLOS
Although SLOS is memory-intensive, it is a complexity-efficient backend, unique to Perceval, for simulating output distributions of linear optical circuits. The 2ⁿ time advantage offered by SLOS is useful for researchers to simulate their theories and verify their experiments, and it is useful for industry to quickly design and validate algorithms.
You can access SLOS through the open-source code on GitHub [8]. Quandela’s tutorial center also includes several applications using SLOS [9–12], which you can run both locally and on Quandela’s quantum cloud service [13].
Article by Filipa Carvalho, Rawad Mezher & Shane Mansfield
1 — Introduction (non-technical summary)
The huge promise offered by quantum computers has led to a surge in theoretical and experimental research in quantum computing, with the goal of developing and optimising quantum hardware and software. Already, many small-scale quantum devices (known commonly as quantum processing units or QPUs) are now publicly available via cloud access worldwide. A few weeks ago, we were delighted to announce Quandela’s first QPU with cloud access — Ascella— a milestone achievement and the first of its kind in Europe.
We are working on developing both quantum hardware and software tailored to our technology. Our QPUs, including Ascella, consist of our extremely high-quality single-photon sources, coupled to linear optical components (or chips), and single photon detectors. We can in principle implement many algorithms on these QPUs, including variational algorithms, quantum machine learning and the usual qubit protocols. Check our Medium profile for more.
This post highlights our latest research: a new important use for our QPUs, namely solving graph problems. Graphs are extremely useful mathematical objects, with applications in fields such as Chemistry, Biochemistry, Computer Science, Finance and Engineering, among many others. Our research shows how to efficiently encode graphs (and more!) into linear optical circuits, in practice by choosing the appropriate QPU parameters, and how to then use the output statistics of our QPUs to solve various graph problems, which we detail below in the technical section. Furthermore, we also show how to accelerate solving these problems using some pre-processing, thereby bringing closer the prospect of achieving a practical quantum advantage for solving graph problems by using our QPUs.
2 — Methods and results
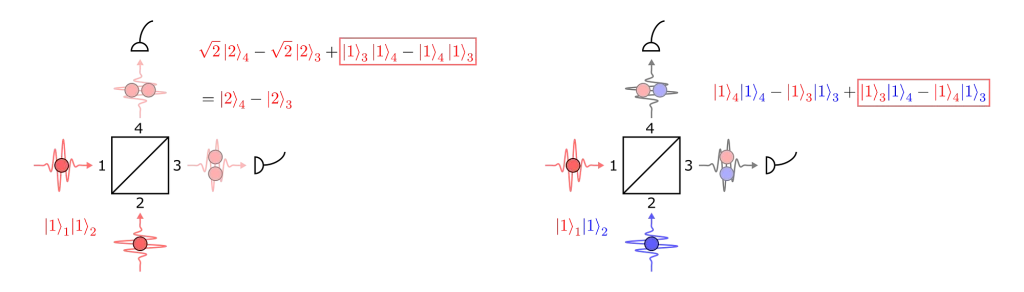
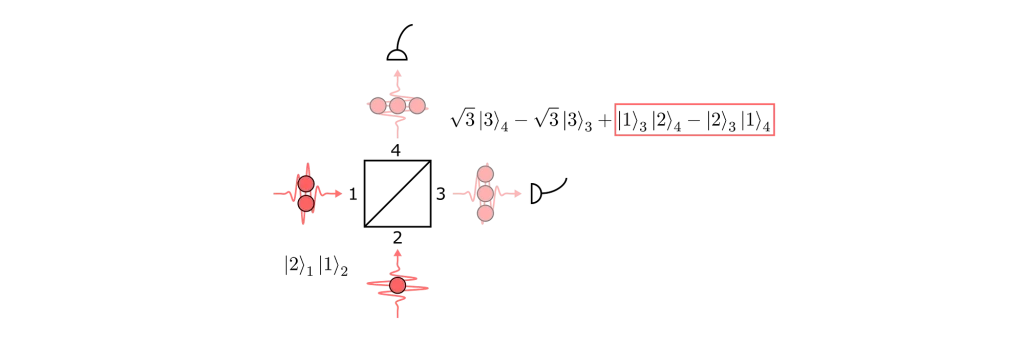
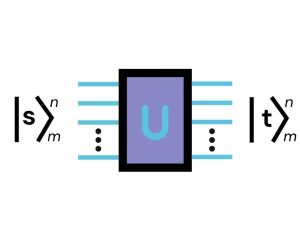
We now take a deeper/more technical look into the workings of our technique. The probability of observing any particular outcome in a linear optical interferometer (say =|n⟩=|n₁,…,nₘ⟩) will depend on the configuration of the interferometer (which can be described by a unitary matrix U) and the input state ( |nᵢₙ⟩=|n₁,ᵢₙ , … , nₘ,ᵢₙ⟩ where nᵢₙ is the number of photons in the iᵗʰ mode in the following way [1]:
(Unᵢₙ,n is a unitary matrix obtained by modifying U based on the input and output configurations and nᵢₙ.) Hence, the applications for such a device relate closely to a matrix characteristic known as the permanent (Per) — a mathematical function that is classically hard to compute. One of the key techniques we use to make matrix problems solvable using our quantum devices is mapping the solution of a given matrix problem onto a problem involving permanents.
2.1 — Encoding, computing permanental polynomials and number of perfect matchings
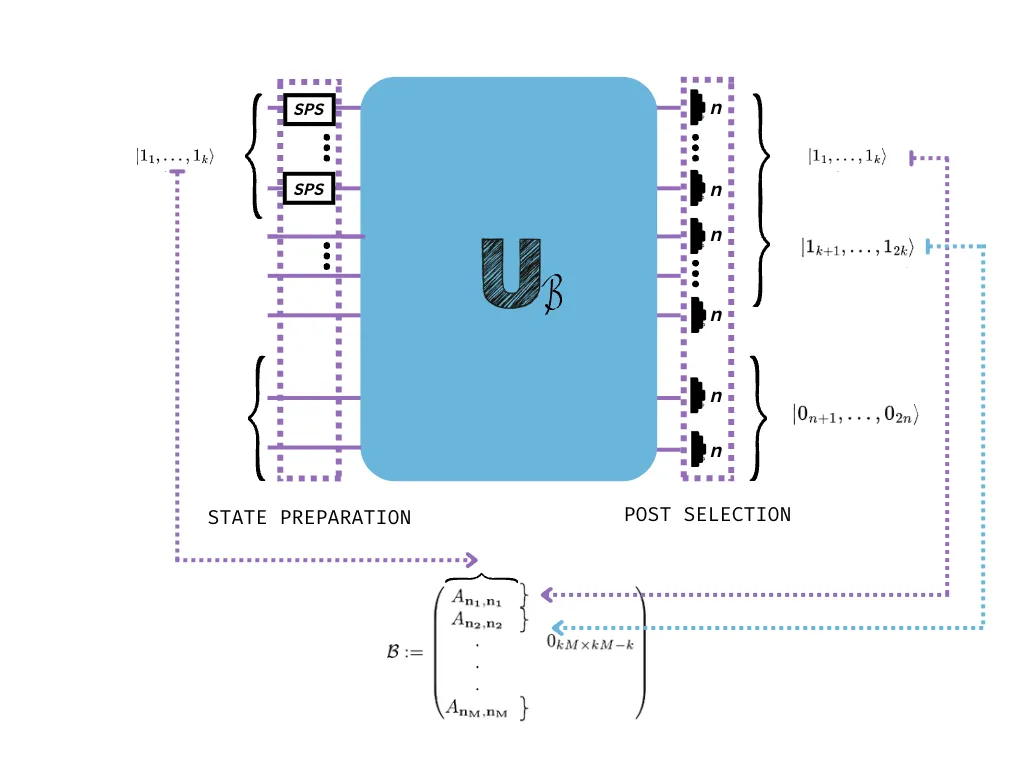
We begin by encoding matrices into our device. Graphs (and many other important structures) can be represented by a matrix. To encode a bounded matrix A, if we consider the singular value decomposition obtaining A = UDV* where D is a diagonal matrix of singular values and take s the largest singular value of A (maximum value of D), we can scale down this matrix into Aₛ = A/s so that we obtain a matrix that has a spectral norm ||Aₛ||≤1. From here, we can make use of the unitary dilation theorem [2] which shows that we can encode Aₛ onto a matrix which is unitary and has the following block form
With the appropriate input and output state post-selection, we can estimate the permanent of A by using a setup similar to that of the figure below (see our paper [6] for details). You can test this estimation for yourself using Perceval, an open software tool developed by Quandela to simulate and run code on a photonic QPU [3].
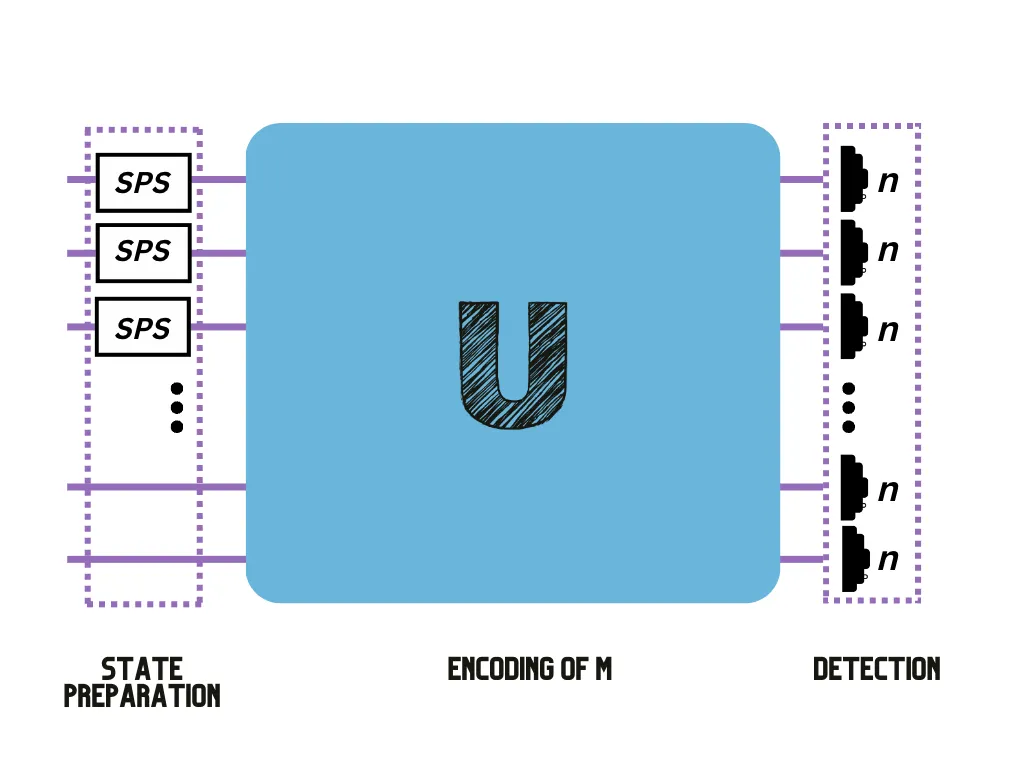
Figure 1 — Setup to estimate a matrix permanent composed of single photon sources (SPS), a linear optical circuit U encoding A, and single photon detectors.
2.2 — The k-densest subgraph problem
The densest subgraph problem is the following: given a graph of n nodes, find the subgraph of k nodes which has the highest density. Considering an adjacency matrix A and the cardinality of nodes |V| and edges |E|, we proved in [6] that (when |V| and |E| are even) the permanent is upper bounded by a function Per(A)≤f(|V|,|E|) where f(|V|,|E|) is a monotonically increasing function with the number of edges.
The connection to the densest subgraph problem is natural since the density of a graph defined by the nodes v is:
where Eᵥ is the number of edges in that subgraph connecting the nodes v meaning that the density is proportional to the number of edges.
Let n be the number of vertices of a graph G. We are interested in identifying the densest subgraph of G of size k≤n. The main steps of our algorithm [6] to compute this are the following:
Use a classical algorithm [5] which finds a subset L of size <k of the densest subgraph of G. Then use L as a seed for our algorithm, by constructing a matrix B of all possible subgraphs of size k containing L. In general, this number of possible subgraphs is exponential however, given the classical seed, this number can be reduced to polynomial in some cases [6].
After constructing the matrix with these possibilities, we choose the appropriate input state and the following post-selection rules:
For clarification, check the figure below.
Each post-selected output computes the permanent of a subgraph, and by the connection established above it follows that the densest one will be outputted the most often, since it has highest permanent value.
We tested our theory and obtained some results (you can find and reproduce them on this link). Here we present an example. Given a graph G represented in the next figure with node labels, we searched for denser subgraphs of size 3 with minimum number of samples from the linear optical device set to 200.
We tested for different seeds that the classical algorithm might have provided.
For [2], 23420000 samples were generated; 200 remained from post selection, all attributed to node group [2,4,5].
For [4], 21120000 samples were generated; 200 remained from post selection which were distributed over node groups [4,3,5] and [4,2,5] with 115 and 85 samples respectively.
Our algorithm outputted the expected subgraphs from the figure and when it had two equally suited options it correctly outputted both.
2.3 — Graph isomorphism
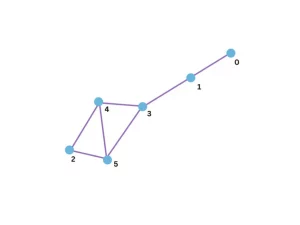
In our paper [6], we prove that computing the permanent of all possible submatrices of the adjacency matrices of two graphs G₁ and G₂ is necessary and sufficient to show that they are isomorphic; however, this is not practical as the number of these computations skyrockets with the number of vertices. One alternative is to import powerful permanent-related tools from the field of graph theory to distinguish non-isomorphic graphs. A powerful distinguisher of non-isomorphic graphs is the Laplacian [4]. Starting with an estimation using the permanental polynomials P(x):
the Laplacian of a graph is given by L(G):= D(G) — A(G) where A(G) is the graph’s adjacency matrix and D(G) is a diagonal matrix where each entry stands for the degree of the corresponding node. Here, in this Laplacian method L(G) replaces A in P(x).
Given two graphs G₁ and G₂, the steps for graph isomorphism are the following:
Encode xIₙₓₙ — L(G) for both G₁ and G₂ into unitaries U₁ and U₂ of 2n modes.
Compute an estimate of Per (xIₙₓₙ — L(G)) for each graph by using the configuration before: passing photons on the first modes of U₁ and U₂ and post-selecting on |n⟩= |nᵢₙ⟩.
Repeat steps 1 and 2 for different values of x. Declare that they are isomorphic (True) if the estimations are close (up to an error).
We tested our algorithm comparing random graphs with similar characteristics (same number of nodes and same edge connectivity) and obtained results as summarized in the pie chart.
This means 75% of the time, all three outputted the same, 93% of the time we got the right result using the Laplacian method, 77% of the time we had a correct answer with just the Permanental, and 5% of the time we did not obtain a correct answer by either of the methods.
2.3 — Boosting probabilities
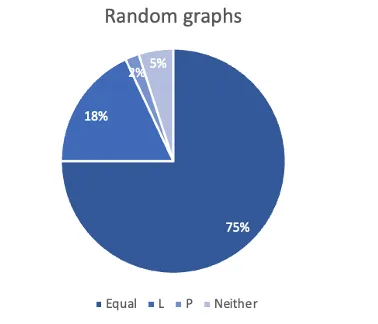
Last but not least, boosting our results. Not only might post-selection reject a considerable portion of our samples, but the advantage to estimate permanents over classical approaches can be hard to verify. To soften this, to have a better run time and increase the prospects of seeing a practical quantum advantage, we studied how to better approximate the permanent with less samples. Put simply, we hack the adjacency matrix by multiplying the row corresponding to the least connected node by a number and encode the new matrix into the device; this might allow us to increase the probability, depending on the connectivity.
In the following table, we give some of the results over different w for the graph on the left.
3 — Conclusion and final remarks
The applications and algorithms we developed were focused on graph problems, but the interesting fact is that our encoding method allows the encoding of any bounded matrix.
An important factor is the complexity of these algorithms. To estimate permanents by sampling, one obtains a polynomially close estimate of the permanent using a polynomial (efficient) number of samples [6]. This rules out the prospect that our algorithms present an exponential quantum-over-classical advantage, as polynomial-time classical algorithms like the Gurvits algorithm [7] can also approximate permanents to polynomial precision. However, it leaves open the possibility that our techniques might present a practical advantage over their classical counterparts.
A final note is that when comparing quantum algorithms to classical ones, a factor which is becoming increasingly relevant is their energy cost. In terms of resources, Quandela’s Ascella QPU (12 modes and 6 photons) has the potential to be more energy efficient when compared to its classical counterparts.
References
1. S. Aaronson and A. Arkhipov, The computational complexity of linear optics (2011) pp. 333–342
2. P. R. Halmos, Normal dilations and extensions of operators, Summa Brasil. Math 2, 134 (1950)
3. N. Heurtel, A. Fyrillas, et al., Perceval: A software platform for discrete variable photonic quantum computing, arXiv preprint arXiv:2204.00602 (2022)
4. R. Merris, K. R. Rebman, and W. Watkins, Permanental polynomials of graphs, Linear Algebra and Its Applications 38, 273 (1981)
5. Nicolas Bourgeois, Aristotelis Giannakos, Giorgio Lucarelli, Ioannis Milis, Vangelis Paschos. Exact and approximation algorithms for densest k-subgraph. 2012. ⟨hal-00874586⟩
6. R. Mezher, A. Carvalho, S. Mansfield, arXiv:2301.09594v1
7. L. Gurvits, in International Symposium on Mathematical Foundations of Computer Science (Springer, 2005) pp. 447–458.
If you are interested to find out more about our technology, our solutions or job opportunities visit quandela.com
Linear optical quantum computation uses photons as carriers of information (i.e. qubits) in an optical circuit with beam splitters and phase shifters that process this information. You can read more about how optical quantum computing works here.
Let different outputs of an optical quantum circuit correspond to different spending models one can obtain with a specific number of photons corresponding to their limited budget. Naturally, the more spending models we have access to, the more options we have to choose from and therefore have a higher likelihood of making an optimal choice. If before we had the categories ‘food’ and ‘travelling’, we will surely benefit from branching out these categories into ‘groceries’, ‘fast food’, ‘restaurants’ and ‘flights’, ‘public transportation’ etc. While we may have given a high importance to the category ‘food’ before as it is essential to our survival, we can now identify that some categories like ‘fast food’ and ‘restaurants’ aren’t as essential as ‘groceries’ so we have a higher chance of making better choices with a limited budget.
For the creation of a good photon spending model, it’s important not only to know how many photons there are in a budget (entered the circuit) and where they were found in the end (on which output modes). It’s important to also quantify the photon expenses on each mode (how many photons are found in which output mode), so you have a better chance of reaching that photon distribution you’re looking for.
Are you looking for a way to do more complex computations with a limited photon budget but you find yourself not knowing your photon distribution at the end of your computation? Fear not, we have you covered! Keep reading to discover how to make the most of your photons with our new feature — pseudo photon number resolution (PPNR or pseudo PNR).
1. Why is PNR important?
The use of photons as quantum processing units has an advantage of satisfying 5 DiVincenzo conditions for building a quantum computer (remind yourself of these by reading this short article). It also gives access to a truncated Fock space, that is larger than the qubit space. We measure this difference by the size of the Hilbert spaces that describe them mathematically. You can read more about the difference between these in one of our previous articles here.
Without PNR, we can only work within a Fock space truncated down to the same size as the qubit space size. The plot above demonstrates the power of PNR in enlarging the computational space size, even with maximum resolution of 2 photons.
In short, using the photonic Fock space gives us a scaling advantage. With the same number of photons, the Fock space is much larger than the qubit space, and therefore allows us to construct and work within a greater computational space. Essentially, we can do more with less, helping you make the most of your photons! This can be viewed as the expansion of the number of categories we consider for our photon spending model we talked about earlier.
We previously stated that we couldn’t count the number of photons in a single output mode with perfect accuracy, limiting our access to some states in the Fock space, i.e. a truncated Fock space. While perfect accuracy is still difficult to achieve, we are happy to share that we have made a great stride towards it!
Perceval users can now configure their modes, declaring them photon number resolving or not. This is an optional feature already introduced in our software and ready for use!
2. PNR integration
You’ve probably heard about microprocessors or classical processing units (CPUs). Think of them as the brains of a computer, processing and analysing information using classical operations. They are connected to other parts of the computer through pins, some of which have a predefined function (meaning that they can only perform one function, such as RESET pins) while others are configurable. These are called general purpose input/output (GPIO) and are much more useful.
An analogy of the same idea of configurable ports can be applied on optical devices in a quantum processing unit (QPU). A QPU differs from a CPU in the way its computations are performed, harnessing the power of physical behaviours occurring with quantum particles.
Photon detection works based on a grid — changing the position and number of photons found in each mode of the grid changes the state of the system (spending model considered). This is why having access to a PNR detector is imperative to achieving high fidelity. A single photon detector (SPD) would only be able to tell us whether it detected any photons at all (giving us the output 1) or none at all (outputting 0). You can visualise the difference between the capabilities of PNR and SPD below.
PNR vs SPD
In simple terms, PNR detectors allow you to analyse your photon distribution better (as they have access to more spending models) so you naturally have a better chance of finding that distribution you’ve been dreaming of obtaining. Now you might be wondering: how is PNR achieved in a photonic quantum computer?
Our newest feature uses balanced beam splitters attached to the modes the user has declared PNR. Recall that a beam splitter is an optical device containing 2 input modes and 2 output modes. It controls the direction of the photons that pass through it. A balanced beam splitter gives a photon entered through either of the inputs a 50% chance of ending up in either of the outputs (the choice is random), as it can either reflect off the beam splitter or be transmitted through it.
transmittance / reflection
Imagine a mode containing 2 photons connected to our PPNR detector. Reaching a balanced beam splitter, these photons will end up either taking the same route and will therefore be found in the same mode with a 50% probability, or they will each go their way and be found in separate modes with a 50% probability.
There are 4 different ways 2 photons might travel through a beam splitter, each equally likely to occur (each with 25% probability)
Case 1: Input 1 and input 2 were both reflected and came out the outputs 1 and 2 respectively.
Case 2: Input 1 was reflected and input 2 was transmitted so they both ended up in output 1.
Case 3: Input 1 was transmitted and input 2 was reflected so they both ended up in output 2.
Case 4: Input 1 and input 2 were both transmitted and came out the outputs 2 and 1 respectively.
Since photons are indistinguishable, we recognise that there’s a 50% probability of the photons splitting up and 50% probability of them ending up in the same mode.
We call this pseudo PNR because we obtain the photon distribution probabilistically and not deterministically. In simple terms, we do not have full control over whether a photon gets reflected or transmitted as this happens randomly, with a certain probability (50%).
We constructed a set-up that manipulates how our photons travel and gives us a good chance of counting 2 photons if they are travelling together in a single mode. An example of a non-pseudo PNR would be PNR that deterministically determines the number of photons in a mode by measuring the intensity of light. The more photons are found in a mode, the stronger their light will be. If we can deterministically measure the brightness, we are 100% confident in the photon count and this would be true PNR.
For now, PPNR can only be used on the first 3 modes of our QPU and its simulator, but this can also help us infer knowledge about other modes. You can test its performance for an up to 2-photon number resolution with 50% accuracy. The feature can easily be implemented in a single line of code, as shown in the picture below.
Stay tuned for future releases on more modes!
This is a great step forward, broadening the limits of what is possible to do in our framework and paving the way for some very exciting applications. In quantum machine learning, it allows us to work with more complex learning models as we are able to work in a larger computational space (Fock space). You can find a simple visual explanation for why that is the case here. Furthermore, in quantum algorithms for classification (VQC), access to PNR allows the creation of a highly expressive ansatz, automatically increasing the complexity of the circuit without increasing the number of photons used. You can explore how and why we use VQC on our very own QPU Ascella here.
So, what are you waiting for? Uncover the full potential of our new feature and make the most of your photons!
If you are interested to find out more about our technology, our solutions or job opportunities visit quandela.com
One of my fondest childhood memories is enjoying the sweet, delicious taste of a large-scale fault tolerant quantum computer. In this article, we’re going to explain how you can bake your own scrumptious quantum processor from scratch. Whether you’re trying to impress a first date, cater for friends, or entrench a technological advantage against your geopolitical rivals, quantum computers are the perfect treat for any occasion.
Difficulty: Extreme
Cooking time: 5–7 years of R&D
In our last article, we answered the question “What is a Quantum Computer?”. As a quick reminder: a quantum computer is a device that uses the principles of quantum mechanics to perform certain calculations much faster than a regular computer.
One of the most common recipes for baking a quantum computer was created by quantum chef/scientist David DiVincenzo. His family recipe lists 5 main ingredients (we’re dropping the cake analogy from here on for clarity):
1. A scalable physical system of qubits
A classical computer uses binary bits with a value of either 0 or 1 to represent information. This is represented physically as tiny switches called transistors inside the computer that are either on or off. Quantum computers often represent information as qubits, which can be in the state |0>, |1>, or a superposition of both states. For a proper explanation of how this works, check out our previous article.
Many different physical systems have been used to generate qubits, including superconductors, ion traps, and photons. It’s important to highlight that the system of qubits must be scalable i.e. we can create larger and larger systems of connected qubits to run larger calculations. The quantum computers available in labs today don’t have enough processing power to tackle real world problems. If a system of qubits can’t be scaled up, we won’t be able to use it to create useful quantum computers.
2. The ability to initialise the qubits to a simple reference state
Imagine trying to do maths on a calculator without being able to erase the answer to the previous calculation, or even check what it was; the errors would be enormous. Initialising states is necessary for both classical and quantum computers, but for quantum computers it’s much more difficult.
The initialisation process varies depending on the qubit’s physical system. Let’s examine the case of photonic qubits discussed in our previous article. In this system, a photon can be in one of two optical fibres. The system is in the state |0> or |1> depending on which fibre the photon is in. A simple reference state for this system would be |0000>, which means that 4 qubits have a photon in the fibre corresponding to their |0> state. To initialise this kind of photonic qubit you need to be able to emit single photons, on demand, into specific optical fibres.
This sounds easy, until you consider how small photons are. A normal LED lightbulb releases quintillions of photons every second. Releasing just one of them (and controlling it) is extremely difficult. Quandela was founded on technology which tackles this very problem, by fabricating semi-conductor quantum dots that act as controllable single-photon sources. You can learn more about our technology in this article.
3. Decoherence times that are much longer than the gate operation times
Most types of qubits are extremely delicate, and they tend to lose their quantum properties (such as superposition, entanglement, and interference) soon after they are initialised through a process called decoherence. Decohering qubits ruin quantum computations, which rely on such quantum properties to deliver all the nice speedups and advantages that they have when compared to ordinary classical computers. So the operations we use to manipulate quantum states (performed by quantum gates) must be fast relative to the lifespan of the qubit, or some of them may decohere before the calculation is finished. In our food analogy, you can’t make a meal using ingredients that will expire before you’re finished cooking them.
4. A universal set of quantum gates
Quantum gates are the quantum versions of the logic gates used in classical computers. They affect the probability of getting a particular answer when the qubits they act on are measured (see previous article for details). Some gates act on one qubit at a time, while others act on two or more. A universal set of gates is a group of gates that you can combine to form any other gate. If you have a universal set of gates, you can perform any quantum operation on your qubits (ignoring gate errors, decoherence, and noise, which we will discuss further in a future article).
5. A qubit-specific measurement capability
There wouldn’t be much point in performing calculations on a quantum computer if you couldn’t record the results. A measurement is said to be qubit-specific if you can pick out a particular qubit and detect what state it is in: usually |0> or |1>. This gives you the result of your quantum calculation as a string of 0s and 1s, which could eventually be fed into a classical computer to design life-saving medicine or decrypt your internet search history.
Quantum Communication
DiVincenzo outlined two additional criteria to allow a device to engage in quantum communication, which is the transfer of quantum information between processors separated by a large distance. These criteria are:
The ability to convert between stationary qubits (used for calculations) and flying qubits (that can move long distances).
The ability to faithfully transmit flying qubits between specified locations.
Quantum communication allows us to connect quantum computers together and combine their processing power to solve problems. Photons are the best option, and in fact probably the only sensible option, for implementing flying qubits, given that they travel at the speed of light, don’t suffer from decoherence over time (although optical components still add noise), and can be directed through optical fibres.
What now?
The DiVincenzo criteria have had an enormous impact on the field of quantum computing research over the past two decades. Unfortunately, they may also restrict our understanding what a quantum computer can be. We will explore this further in the next article of this series, which explains why the number of qubits in a quantum computer doesn’t necessarily measure how advanced it is.
Having read this and the previous article, you should now have a basic understanding of what quantum computers are, how they work, and what it takes to cook one up from scratch. Follow Quandela on Medium to learn more about quantum computing from one of the most advanced companies in the field.
Disclaimer: Cooking time may vary. Quantum computers are hardware devices which may be composed of high energy lasers, powerful magnets, and silicon chips at temperatures close to absolute zero. They are not food. Please do not attempt to eat a quantum computer. Quandela does not accept any liability from readers attempting to consume the components of a quantum computer.
Quantum computing has the potential to be one of the defining technologies of the 21st century, with practical applications that could completely transform modern society. Despite its enormous significance, most people have absolutely no idea what quantum computing is.
In this article, we’re going to explain what quantum computers are and give a brief introduction to how they work. You don’t need a background in science to follow along, just a few minutes of spare time and a desire to learn.
What’s the definition?
A quantum computer is a device that uses the principles of quantum mechanics to perform certain calculations much faster than a regular computer. When we say faster, we don’t mean that scientists will spend less time waiting around for their results. A future large-scale quantum computer could solve problems that would take millions of years on today’s best supercomputers (1,2).
These problems aren’t just abstract maths puzzles, they’re real-world challenges that will have a massive impact on people’s lives. Quantum simulations of chemical reactions would enable the discovery of life-saving medicines, advanced materials, and sustainable manufacturing processes (3–5). Quantum algorithms could lead to breakthroughs in artificial intelligence, while quantum cryptography could provide unbreakable data encryption secured by the laws of physics[1] (6,7). The significance of these applications has led to a lot of hype around quantum computing, eagerly fed by companies in the industry looking to secure customers and raise funding. To cut through this hype and understand the underlying technology, we need to look at some fundamental physics.
What is Quantum Mechanics?
The basis of quantum computing is quantum mechanics, which is a scientific theory that describes the behaviour of the basic building blocks of our universe, like atoms, electrons, and photons[2]. Let’s quickly define two important terms: a “quantum system”is something whose behaviour can be explained through quantum mechanics, and a “quantum state” is the mathematical description of a quantum system.
The key principles of quantum mechanics that you’ll need to understand quantum computing are entanglement, interference, and superposition:
Entanglement: When a group of particles are entangled, measuring one of them instantly causes a change[3] in the others, even if they are vast distances apart. In technical terms, the quantum states of entangled particles can’t be described independently of one another.
Entanglement doesn’t exist in our large-scale everyday world, so it can be hard to wrap your head around it. As an example, imagine that we had a pair of entangled quantum coins, which each exist as a combination of heads and tails at the same time until we measure them[4] (I never said it would be a good example). If I flipped one of the coins and it landed on heads, then I could know with 100% certainty that yours would be tails before you’d flipped it. The instant its entangled partner was measured, your coin was in the state tails, instead of the combination of heads and tails it was the moment before.
Interference: Interference is a phenomenon where overlapping waves combine or cancel out. It’s how noise-cancelling headphones work: they emit sound waves that interfere destructively with background noise. A simple diagram of destructive interference is shown below:
Waves canceling out through interference
Quantum particles can act like waves, so they experience quantum interference. The maths describing quantum interference is a bit different to regular interference, but the general idea is the same.
Superposition: A quantum state can be described mathematically as the sum of other quantum states. This is another similarity between quantum states and waves, which can be described as the sum of other waves. The quantum coin existing as a combination of heads and tails in our entanglement example was in a superposition of heads and tails.
Quantum mechanics is one of the most stunningly accurate scientific theories in history, but an engineer would never use it to design a car or a bridge. Instead, they’d use the rules from a less precise group of theories known as classical physics.
Classical physics is a set of approximations and simplified rules used to describe the stuff we interact with every day (heat, sound, motion, gravity, etc.). These are the laws of physics you probably studied in school. When many quantum objects interact, it becomes easier to describe their collective behaviour using classical physics rather than quantum mechanics. A football is made of atoms, but you don’t need quantum physics to predict what will happen if you kick it. “Classical” in this context refers to the non-quantum, large-scale, everyday world of footballs and kicking that we live in.
To explain how quantum computers use entanglement, interference and superposition to perform calculations, we’re going to examine qubits: the fundamental components of (most[5]) quantum computers.
What is a Qubit?
A classical computer like the device you’re reading this on uses bits to represent information. A bit can have a value of 0 or 1, like a switch that is either on or off. Modern computers are made of billions of these tiny switches, allowing them to perform complex tasks such as delivering your daily meme supply. For instance, the word “Hi” is stored in a computer (using ASCII binary code) as 1001000 1101001. As well as storing information, computers perform calculations using bits: 2 + 2 = 4 is represented in binary as 10 + 10 = 100.
The quantum version of a bit is called a qubit. Physically, a qubit is just a two-level quantum system. One example of a qubit is a photon that can be sent down either of two optical fibres. An optical fibre is a wire made of flexible glass or plastic that reflects photons internally. It can be used to transport light like copper wire carries electricity.
If the photon is in the first of the two fibres, then the qubit is in the state |0>. If the photon is in the second fibre, then the qubit is in the state |1>. When you measure the state of this qubit by detecting where the photon is, you’ll get a classical 0 or 1. This is shown in the diagram below:
Travel path photonic qubits
Quick note: |x> is how we write a quantum state in Dirac notation, which is a convention that makes quantum physics calculations easier.
One of the weird features of quantum mechanics is that a single photon can be sent down both fibres at the same time, as a superposition of the two states. Measuring the photon causes the superposition to collapse, and the photon will be found in one fibre or the other. Qubits existing in a superposition is one of the key differences between quantum and classical computing, which will be discussed further in the next article of this series.
How do we use this for calculations?
A qubit-based quantum computer is generally composed of three stages:
1. Initialisation: The qubits are given a known value when the calculation starts, such as every qubit being in the state.
2. Manipulation: A quantum circuit uses interference and entanglement to apply mathematical operations to the qubits.
3. Measurement: The quantum states of the qubits are measured to read the results of the calculation.
An example of this structure can be seen in the following diagram of a photonic quantum computer:
Architecture of an optical quantum computer
At the end of a calculation, the qubits in a quantum computer exist in a superposition of all the possible outcomes. When you measure the qubits, you collapse this superposition, and get one of the possible outcomes at random as your answer. Quantum algorithms can be designed so that the quantum states in the superposition corresponding to the wrong answers interfere destructively and cancel out, leaving behind only the right answers. Entanglement is used to connect qubit superpositions together to perform useful calculations.
By running the circuit and measuring the qubits hundreds or thousands of times, we can build a graph of how likely each of the possible outcomes are. This graph (a probability distribution) is the final result of our quantum calculation.
The process of manipulating probabilities with superposition, interference, and entanglement is fundamentally different to how normal computers operate. That is why quantum computers can do certain tasks so quickly: they’re not better than classical computers in general, they just work differently. Quantum computers are much better suited to mundane supercomputer-style tasks like designing medicines than crucial everyday tasks like posting memes, so they are expected to co-exist with classical computers rather than replacing them entirely. Many of the most famous quantum algorithms actually use a combination of quantum and classical techniques to solve problems[6].
What’s next?
Hopefully this explanation has given you a basic understanding of what a quantum computer is. In the next article in this series, we’re going to examine how a quantum computer works in more detail, hopefully without getting lost in technical jargon.
If you are interested to find out more about our technology, our solutions or job opportunities visit quandela.com
Footnotes:
1. Optical quantum communications can provide data protection through security protocols such as BB84, while quantum computers will be able to factor large numbers using Shor’s Algorithm and break modern RSA encryption. There are, however, non-quantum encryption techniques that are immune to Shor’s algorithm.
2. Atoms are not elementary particles like quarks and gluons, but they are still small enough to be described with quantum mechanics. Quantum mechanics is also needed to explain certain behaviours of some large-scale objects like black holes and neutron stars.
3. Entanglement is a slippery subject. Technically change occurs in the quantum states of the other particles; i.e. their mathematical descriptions. An important side point is that the change is not directly observable, except through clever strategies which involve comparisons of observations on each particle. If the changes were directly observable it would provide a means of instantaneous (faster-than-light) communication across great distances — something that’s already disallowed by relativity, one of our other great theories of physics.
4. Maybe you could begin to wonder at this point whether this combination of heads or tails is really all that strange… After all I could perform a coin flip, close my fist around it to catch it, and until I open it again I won’t know if it’s a head or a tail. That’s a kind of combination of heads and tails too, right? Well, yes, but this is where everyday and quantum coins begin to differ. The everyday coin really is just one or the other, and all that’s really happening is that I’m ignorant and don’t have the information about which one it is yet. On the other hand, a quantum coin can really be in a superposition of both heads and tails. And we can know that it’s in a genuine superposition by doing clever experiments that look for interference effects.
5. Photonic quantum computers can demonstrate quantum advantage using a technique called Boson Sampling without encoding information as qubits. We will explain this in detail in a future article.
6. Some examples of quantum-classical algorithms include Shor’s Algorithm (8), VQE (9), and QAOA (10).
References
1. Arute F, Arya K, Babbush R, Bacon D, Bardin JC, Barends R, et al. Quantum supremacy using a programmable superconducting processor. Nature. 2019 Oct;574(7779):505–10.
2. Madsen LS, Laudenbach F, Askarani MFalamarzi, Rortais F, Vincent T, Bulmer JFF, et al. Quantum computational advantage with a programmable photonic processor. Nature. 2022 Jun 2;606(7912):75–81.
3. Kirsopp JJM, Di Paola C, Manrique DZ, Krompiec M, Greene-Diniz G, Guba W, et al. Quantum Computational Quantification of Protein-Ligand Interactions [Internet]. arXiv; 2021 [cited 2022 Jul 19]. Available from: http://arxiv.org/abs/2110.08163
4. Clinton L, Cubitt T, Flynn B, Gambetta FM, Klassen J, Montanaro A, et al. Towards near-term quantum simulation of materials [Internet]. arXiv; 2022 [cited 2022 Jun 24]. Available from: http://arxiv.org/abs/2205.15256
5. Greene-Diniz G, Manrique DZ, Sennane W, Magnin Y, Shishenina E, Cordier P, et al. Modelling Carbon Capture on Metal-Organic Frameworks with Quantum Computing [Internet]. arXiv; 2022 [cited 2022 May 17]. Available from: http://arxiv.org/abs/2203.15546
6. Havlicek V, Córcoles AD, Temme K, Harrow AW, Kandala A, Chow JM, et al. Supervised learning with quantum enhanced feature spaces. Nature. 2019 Mar;567(7747):209–12.
7. Bennett CH, Brassard G. Quantum cryptography: Public key distribution and coin tossing. Theor Comput Sci. 1984 Dec;560:7–11.
8. Shor PW. Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer. SIAM J Comput. 1997 Oct;26(5):1484–509.
9. Peruzzo A, McClean J, Shadbolt P, Yung MH, Zhou XQ, Love PJ, et al. A variational eigenvalue solver on a quantum processor. Nat Commun. 2014 Sep;5(1):4213.
10. Farhi E, Goldstone J, Gutmann S. A Quantum Approximate Optimization Algorithm [Internet]. arXiv; 2014 [cited 2022 Jul 20]. Available from: http://arxiv.org/abs/1411.4028