
Current quantum computing infrastructures were designed around a cloud execution model in which the Quantum Processing Unit (QPU) is treated as a remote resource. In this model, a machine learning workload running on a GPU must hand data back to a classical host CPU, which coordinates the application workflow and quantum job submission. The system then submits the quantum job, waits for scheduling, executes it on the QPU, retrieves and deserializes the results, and finally transfers tensors back to GPU memory before inference can continue. While acceptable for experimentation and offline workloads, this architecture introduces latencies measured in seconds and prevents tight coupling between AI models and quantum processors.
This limitation is especially visible in Quantum Machine Learning (QML), where a quantum layer may need to be evaluated repeatedly inside a neural-network forward pass. Even when the quantum computation itself takes only a few milliseconds, orchestration overhead — network communication, scheduling, serialization, CPU–GPU transfers, and software frameworks — dominates the total execution time. In practice, the full end-to-end latency for a single datapoint through a conventional cloud quantum stack is at least 5 seconds, and often more due to queueing and interleaving with other users’ jobs.
Photonic quantum processors change this cost model. For many photonic QML workloads, the optical circuit remains largely unchanged throughout inference: the processor is configured once, and successive datapoints require only lightweight updates to input-encoding phases before measurement. This allows a fixed optical configuration to be amortized across many samples and many inference calls, with current Quandela processors acquiring approximately 1000 useful samples in ~10 ms.
As a result, for these workloads, the dominant bottleneck shifts from quantum execution to the classical infrastructure surrounding the processor. The challenge is no longer only making the QPU faster, but eliminating the software, networking, scheduling, and memory-transfer overhead that prevents it from operating as part of a real-time computing pipeline.
We propose a new execution model enabled by NVIDIA NVQLink, in which GPUs, Quantum System Controller (QSC), and photonic QPU are physically collocated in an HPC-style environment and connected through a low-latency interconnect. Prior to inference, the controlling CPU reserves the QPU node and preconfigures the optical circuit. During the inference session, the QSC has exclusive control of the QPU, while GPU kernels communicate with it over the NVQLink connection, bypassing host orchestration, remote APIs, schedulers, and repeated memory transfers. The QSC updates the photonic processor, acquires samples, computes observables, and is designed to return results into GPU-addressable memory so the neural network can continue execution immediately.
This architecture transforms the photonic QPU from a remote scientific instrument into a low-latency accelerator participating directly in AI inference — a capability that cannot be achieved when the GPU and QPU communicate only through conventional remote cloud interfaces.
1. Why Current Quantum Cloud Architectures Fail for AI Inference
Modern AI systems are built around tightly integrated accelerators operating on shared memory spaces with predictable latency. GPUs became the foundation of modern machine learning not only because of their computational throughput, but because they can participate directly in training and inference pipelines with microsecond-scale communication and scheduling overhead.
Current quantum computing infrastructures operate according to a fundamentally different model. A QPU is typically exposed as a remote service accessed through APIs and schedulers. In this model, every inference request requires transferring tensors from GPU memory back to a classical host CPU, which coordinates the application workflow and quantum job submission. The system then transmits the request through the software stack, waits for scheduling, executes it on the quantum processor, collects the measurement results, and finally reconstructs the data before returning it to GPU memory.
In addition, quantum processors are not passive compute devices. They are complex physical systems that may require periodic calibration, stabilization, or health checks to maintain operating conditions. In a shared cloud environment, such system-level procedures can interrupt a workload between two consecutive datapoints, further undermining the deterministic latency required for real-time inference.
This architecture was designed for scientific experimentation where throughput is less important than resource sharing and reproducibility. It works well for running isolated quantum circuits, but becomes problematic for hybrid AI workloads in which quantum computation is only one stage of a larger inference pipeline.
In practice, the latency introduced by networking, serialization, scheduling, queueing, and CPU–GPU transfers reaches at least 5 seconds per data point under typical conditions, and often far more when jobs are interleaved with other users’ workloads — even though the quantum execution itself requires only a few tens of milliseconds. A quantum operation that physically requires only a few milliseconds may translate into several seconds of end-to-end latency when executed through a conventional cloud quantum stack.
As a result, today’s QPUs behave as remote scientific instruments rather than compute accelerators. This prevents their integration into real-time AI systems and severely limits the practical deployment of Quantum Machine Learning models.
2. Why Photonic Quantum Machine Learning Changes the Equation
The challenge is not solely architectural. The execution model of the quantum hardware itself determines whether real-time integration is feasible.
On many quantum computing platforms, each execution requires replaying a time-sequenced control program: state preparation, hardware control pulses or operations, measurement, and often reset. Even when the logical circuit is unchanged, this sequence must be repeated for each shot and each new input. Accumulating sufficient statistics therefore multiplies this cost further, a double overhead absent in photonic systems.
Photonic QML has a different cost model. In many photonic models implemented within the MerLin framework [1] — including quantum reservoirs, quantum kernels, and hybrid quantum layers — the optical circuit is persistent: the interferometric transformation is configured once and then reused across many inference calls. Successive datapoints are encoded through small updates to input-dependent phases, while many samples can be acquired from the same physical configuration.
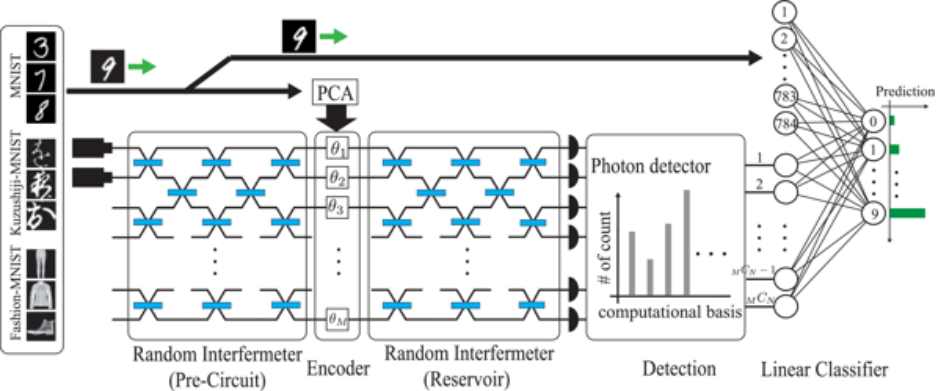
This distinction is crucial because it shifts the cost model of quantum inference. Instead of replaying a full control sequence or fully reconfiguring the photonic interferometer for each datapoint, the processor performs lightweight phase updates followed by sample acquisition.
On current-generation Quandela hardware:
- Full chip configuration: ~1 s (performed once per session)
- Incremental phase update (few phases): ~20 ms
- Sample acquisition (~1000 samples at ~100 kHz effective event rate): ~10 ms
- Total quantum processing per datapoint: ~30 ms
Several observations follow. First, the expensive operation — full chip configuration — is performed only once at the start of the session and amortized across thousands of inference requests. Second, the per-datapoint quantum workload is measured in tens of milliseconds. Third, if a quantum datapoint is processed in ~30 ms on the hardware, a conventional cloud path requiring ≥5 s spends more than 99% of its time outside the quantum processor.
This observation fundamentally changes the optimization target. The challenge is no longer accelerating quantum execution — it is eliminating the software, networking, scheduling, and memory-transfer overhead that surrounds it. Photonic QML is arguably the quantum workload where reducing orchestration latency delivers the largest end-to-end improvement relative to accelerating the quantum computation itself.
3. Architecture
The proposed architecture introduces two key mechanisms.
3.1 Session-Based QPU Reservation
Before inference begins, the controlling CPU initiates a reservation sequence:
CPU → reserve QPU → assign dedicated worker → preconfigure photonic chip → hand off control to QSC
The photonic processor is locked for the duration of the session. The QSC becomes the sole owner of the quantum resource during execution. This guarantees:
- No queueing or scheduler delays
- No interleaving with other users’ jobs
- No system-level calibration or maintenance procedure interrupting the inference sequence
- Deterministic, real-time latency throughout the session
When the session ends or no further tasks are received from the GPU, the QSC releases the QPU lock and reports the token processing count to the controlling CPU for credit accounting.
3.2 Direct GPU ↔ QSC Communication via NVQLink
The hardware path demonstrated on a DGX Spark system is:
GPU → ConnectX-7 (QSFP) → FPGA/QSC → Photonic QPU
Using NVQLink [2] sub-millisecond networking, inference data bypasses the host CPU, Python runtime, REST APIs, remote schedulers, and serialization layers entirely. The QSC receives encoded input features from the GPU kernel, updates the photonic phase parameters, acquires measurement samples, computes the required observables, and writes the results into GPU-addressable memory. The forward pass then continues immediately on the GPU without returning through the host orchestration path.
This reverses the usual framing of NVQLink. While a Real Time Host containing GPUs can act as a compute resource for the Quantum System Controller, this architecture also explores the complementary direction: enabling the GPU to consume quantum computation as a low-latency accelerator service. In this model, the photonic QPU participates directly in the AI inference pipeline, closer in role to a specialized accelerator than to a remote experimental instrument.
3.3 Resulting Execution Flow
Using NVQLink results in a highly optimized path directly from the GPU kernel to the Quantum System Controller, which controls the photonic QPU during the active inference session. The diagrams below compare the conventional cloud-style execution path with the proposed NVQLink-enabled colocated workflow.
The CPU is removed from the critical path during active inference iterations. No serialization, no repeated host-device copies, no network scheduling.
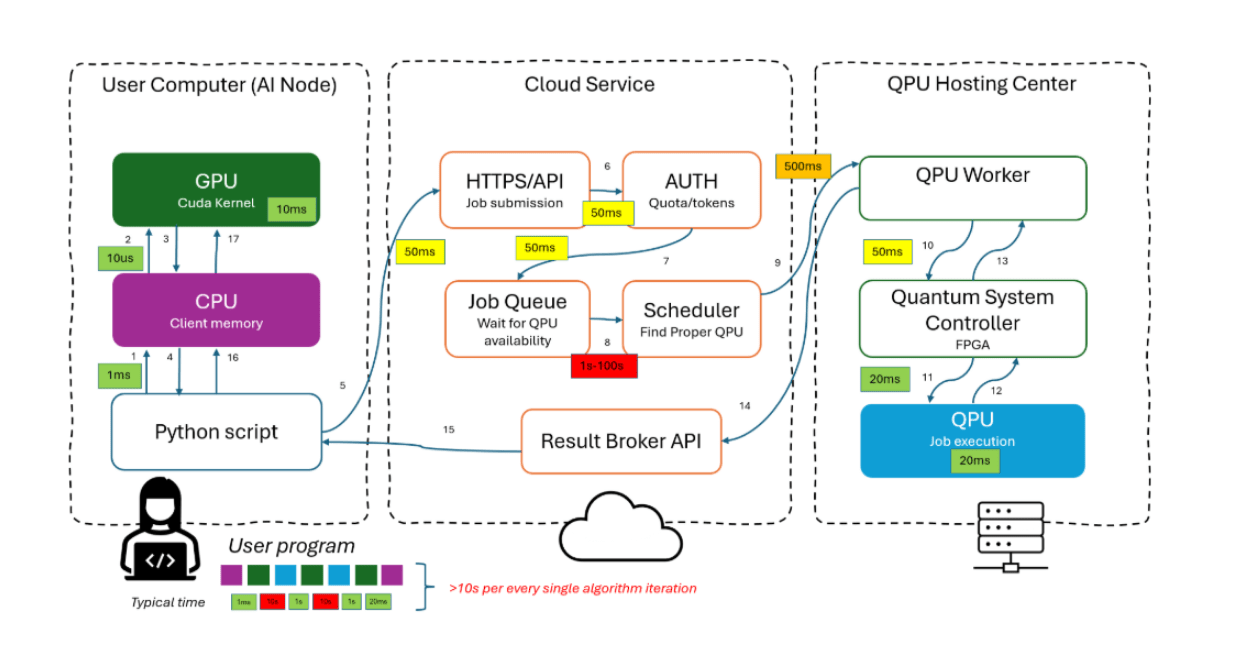
Each iteration traverses cloud APIs, queues and schedulers before reaching the QPU.
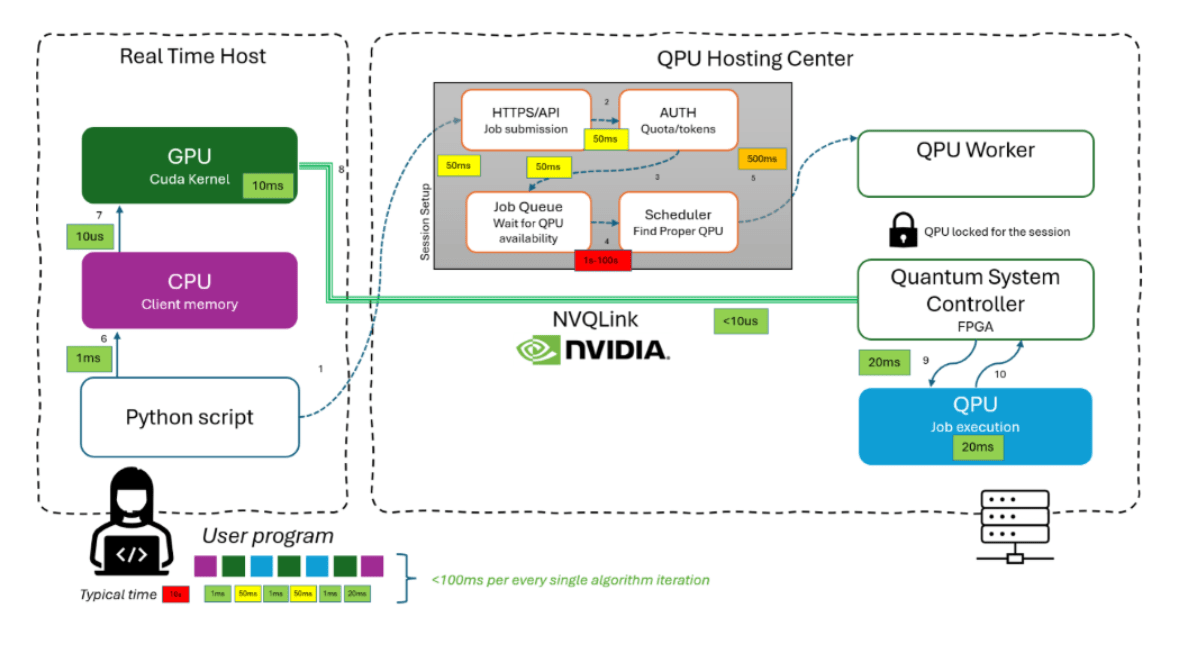
After session setup, the Real Time Host communicates with the Quantum System Controller through NVQLink.
4. Why This Architecture Is Specific to Photonics
This architecture relies on three properties that are particularly favorable in photonic processors.
Fast sampling. Current Quandela processors operate at 80 MHz repetition rate, with effective event rates approaching 100 kHz. Obtaining approximately 1000 useful samples therefore requires only ~10 ms. This fast acquisition rate is essential for QML inference, where observables must be estimated repeatedly across many datapoints.
Persistent configuration with lightweight input updates. In many photonic QML workloads, the interferometric transformation remains fixed throughout the inference session. Moving from one datapoint to the next requires updating only a small number of input-encoding phases, rather than fully reconfiguring the chip. This incremental update takes ~20 ms, compared to ~1 s for a full chip reconfiguration. This model is especially aligned with photonic QML architectures in MerLin [1], where trainable interferometers remain fixed and inputs are injected through lightweight encoding operations.
No replay of a full control sequence between samples. On many other quantum platforms, each shot requires replaying a time-sequenced execution cycle, including state preparation, control operations, measurement, and often reset. Even on fast platforms such as superconducting qubits, this can limit practical sampling throughput to the kHz range. By contrast, once the photonic circuit is configured, samples are acquired from the same physical optical transformation without re-executing a full control sequence between samples.
The result is:
One configuration → Thousands of inference calls
rather than:
One configuration → One execution
This dramatically improves accelerator utilization and is currently not achievable on any other quantum computing platform.
5. Implications for Quantum Machine Learning
MerLin [1] was designed to embed photonic quantum models directly into standard AI workflows and hybrid PyTorch pipelines.
Today, most QML demonstrations operate in an offline regime:
dataset → quantum processing → save results → continue training
The proposed architecture enables:
GPU inference → quantum layer → GPU inference
within a single forward pass, making the following practical:
- Quantum Reservoir Computing
- Quantum Feature Maps and Kernel Approximations
- Hybrid CNN–Quantum and Transformer–Quantum Architectures
6. Energy Efficiency
A further motivation is energy efficiency. Recent work has demonstrated energetic advantage for photonic quantum computing before computational advantage is reached [3]. Consequently, even when classical simulation remains feasible for small systems, direct physical execution on a photonic processor may offer lower energy consumption per inference operation than digital simulation of the same optical transformation.
In this context, coupling GPUs and photonic QPUs at low latency creates a path toward lower energy consumption and real-time operation not only by exploiting the properties of quantum hardware itself, but also by reducing the system-level overhead that dominates hybrid inference today.
7. Conclusion: Toward Hardware Hybridization of Quantum and GPU Computing
The key implication is that useful quantum-classical acceleration for AI inference is not achieved by exposing the QPU as a remote cloud endpoint. It requires a hardware hybridization architecture in which the GPU, QSC, and photonic QPU are physically colocated inside an HPC-style environment and connected through an NVQLink low-latency interconnect. In this setting, the QPU can collaborate with the GPU during a single forward pass, acting as a real-time accelerator rather than as an external batch-processing service. If the GPU is remote from the QPU — for example on a user workstation or in a separate cloud environment — the latency advantages disappear and the system reverts to the limitations of conventional quantum cloud execution.
In this sense, NVQLink-enabled photonic QML is not merely a faster access path to a QPU. It is a step toward effective hardware hybridization between quantum processors and GPU-based AI infrastructure.
References:
[1] MerLin framework — https://arxiv.org/pdf/2602.11092
[2] NVQLink — https://arxiv.org/pdf/2510.25213
[3] Energetic advantage of photonic quantum computing — https://arxiv.org/pdf/2601.08068